https://developer.jboss.org/blogs/mark.little/2015/11/15/is-java-ee-still-relevant
I had a great time at JavaOne this year and Red Hat
had a fantastic showing, with many sessions at the event, many more booth sessions (which were packed out as usual) and of course I made a brief appearance during the kickoff keynote. There had been a lot of interest in this event due to some recent events and rumours about what Oracle would or wouldn't say, specifically about the future of Java EE. This was even a topic of conversation during the
JCP EC face-to-face meeting preceding JavaOne. But nothing much really happened and life, it seemed, would go on as usual. However, there was still a lot of discussion during several sessions and through the usual chatter on the floors or parties about the relevancy of Java EE these days.
But let's face it, this isn't a question that is only being asked in 2015; I've been involved in enterprise Java since before it was called J2EE and within a few years of bring created people were asking the same question. As I've
mentioned many times over the
past few years, people have asked the question when Web Services came along, then REST,
PaaS/Cloud, mobile and now IoT. Each time the concept of middleware has evolved and Java EE, and its associated implementations, with it. People get hung up on the concept of Java EE and application servers as bloated, monolithic entities without actually looking at the reality of today's implementations (well, at least
one). However, I'm
not here to repeat what I've said
time and time again(remember
this from 2011?), most recently at
HPTS 2015. Approaches such as
WildFly Swarm and the massive interest it has seen, show that there's still a lot of interest. And I've already suggested how Java EE can fit into the
next generation platforms.
Rather than revisit this question, which I think I've answered sufficiently, I wanted to link to Ian's entry on the
JavaOne session he did, which I attended. It's always good to hear from someone else on the topic, though I'm sure some will argue he's not objective about this and neither am I. If you're still not convinced, think of the core capabilities within any Java EE application server, such as transactions, messaging, security, cacheing etc; services/capabilities that are needed way beyond Java and Java EE, pre-dating Java by decades and used together or independently in many applications. You can consider Java EE as a way of packaging these things together into a convenient bundle, where they are guaranteed to work well together or independently, and in most cases you probably don't even know they're there. Over the years, before Java was created and way beyond when it is just a mention in history books, that packaging will change but you'll still have something recognisable within middleware implementations, perhaps not co-locating services, perhaps not all implemented in the same language etc. And your future applications will probably not be able to tell the difference or know they're there ... again.
So whilst I think the original question is an important one to ask, I think a much better question is "Where should I use the core capabilities within Java EE?" And if you've got a suitably flexible and agile application server implementation, your application won't need to care that Java EE is, or is not, under the covers providing the desired dependability and reliability.
Of course microservices are the future. Ok, maybe there was a hint of sarcasm in that last sentences! Microservices have a role to play, just as SOA does (yes, I still believe the two are closely tied). There is some truth in there though: more streamlined, agile and dedicated services will be the basis of future application development, whether using (immutable) containers such as Docker or just the standard JVM, perhaps with fatjars. However, anyone who believes that the future of software (middleware) will appear instantaneously has obviously not looked back at other transitions, such as bespoke-to-CORBA or CORBA-to-J2EE. These things take time and evolution rather than revolution is the natural approach. Even if you've not been involved in middleware there are similar examples elsewhere in our industry: COBOL really is still in deployment today! Look at the interest we have around Blacktie!
Therefore, the future will evolve. Yes people will want to develop new applications (so called greenfield sites) using the latest and greatest framework or stack. But they'll also want to integrate with existing business logic and services written in a variety of present day technologies. So there'll still be Java EE application servers (e.g., EAP) with business logic within them, some of it legacy, some written from scratch today and into the future, despite what some may believe.
I believe that due to the fact Java EE has been the dominant non-Microsoft development and deployment platform for well over a decade, there are so many developers out there who are comfortable with it. Yes some may complain about the apparent bloat of implementations, but the reality is that it's still very easy to develop against and use from a variety of different programming languages. That's why the evolution towards any new paradigm is going to be heavily influenced by it, if not driven directly by those developers. So yes, I believe that microservices and Java EE go hand in hand for a large percentage of developers. Approaches such as WildFly-Swarm offer precisely what I'm describing: a comfortable entry point for developers and even existing applications, yet the power to move to a more flexible DevOps driven paradigm. WildFly, when used correctly, offers a mature and easy to use platform that has a minimal footprint and faster boot times than the most popular web servers around! And don't forget that Swarm builds on WildFly so we immediately get the maturity of implementations(s) from it.
However, this mad rush towards microservices, trimming of application servers, creation of applications from fatjars etc. needs to be approached with caution. Our industry is renowned for offering panaceas to problems that require throwing away all we've done before and relearning all of those hard earned lesson! We've got to break that cycle and in Red Hat we've got the pieces to do so: with so many open source projects out there purporting to be right for enterprise applications and new ones springing into life almost on a daily basis, it's easy to understand why people believe every new project is good enough for their requirements. Although I believe open source is a superior development methodology, it takes time and effort to build enterprise-ready components such as transaction servers, messaging brokers, etc. They don't just spring into life ready formed and fully capable. "Good enough" is rarely sufficient for enterprises. It's the edge cases like management, reliability, recoverability, scalability and bullet proof security that are hard to do and get right, yet it's precisely those edge cases that matter time and again. Through core development or acquisition, we've built up a stack that is mature and capable. Whether deployed as a stack or individual pieces, it's what we should be building the next generation of middleware solutions upon. A strong base exists today and we need to reuse as much of that as possible rather than rewrite from scratch in some new popular programming language.
Now as I hinted above, maybe we don't package our future stack or platform in quite the same way as we do today. Microservices offers an approach that is in line with the kinds of trimming we've been seeing anyway. Bundling individual components from the application server as easily deployed (container based) services that can then be exposed to other programming languages, frameworks, solutions etc. is definitely part of the overall solution space. Those core services, such as transactions or storage, could be deployed as individual services or, as is more typical with something like Swarm, deployed with the business logic that uses them. I keep coming back to the JBossEverywhere initiative we had a few years ago - ahead of its time!
Ok so we've looked to microservices and how Java EE fits in. But that can't be the entire answer - and it isn't. As I've mentioned before, at least for a very important set of applications and use cases the future is reactive and event driven. Now that could mean Node.js but just as likely in the Java world it probably means Vert.x. Note, given that many of the Java EE APIs aren't reactive or asynchronous in nature then we'll need to evolve them if we wish to tie them in to Vert.x and I do think we need to do that. Whilst some people will want to develop their applications and microservices in Vert.x from scratch, others will want to tie in legacy systems or have access to some of the core services I mention earlier. I see Vert.x as the ideal backbone or glue that brings all of these things together. The mature core services that we've got are precisely the sorts of things that enterprise developers will need for their applications as they grow in complexity - and let's face it, eventually many applications are going to need security, transactions, high performance messaging etc.
In the Java world the unit of containerisation is essentially the JVM. However, most Java developers realise that unless you ship a farjar, which contains everything you need to run your application/service, it's often typical to find that changes in third-party jars downloaded at deployment time can result in the application or service failing to run first time. This is where operating system containers, such as Docker, really come into their own. The ability to create a deployment unit which runs first time and every time is crucial! Container orchestration technologies, such as Kubernetes, are likewise important if you want to deploy services (via Containers) which are highly available, load balanced etc. Therefore, hopefully it's not too difficult to see where Containers will fit into the future architecture - not mandatory by any means, but definitely a piece of the puzzle which should be considered from the outset.
The combination of OpenShift for Container deployment and management, with Fabric8 for developer experience with CI and CD, provides a compelling hybrid cloud environment, especially once you consider all of the JBoss/Fuse middleware integrated, i.e., xPaaS. As I've mentioned before though, xPaaS isn't about simply adding the middleware products to OpenShift; we're also going to make them much more cloud-aware/cloud-enabled. This has a number of implications, but the one I want to mention specifically is that the core capabilities will be made available to developers in a more cloud-natural manner, e.g., users who want reliable messaging won't need to understand the various intricacies of JMS to use A-MQ and in fact won't even have to know A-MQ is working under the covers. And yes, for those of you still paying attention, those core capabilities I mentioned are precisely the same core services we covered earlier on. See the connection?
Up to this point we've really been playing in the traditional enterprise deployment arena: clients, middle tiers and servers. The cloud comes into play here at the back tier (servers), but what about mobile, IoT and ubiquitous computing? I've discussed this a few times before so won't repeat much here except that I think everything we've discussed so far has immediate applicability for ubiquitous computing and that mobile, as well as IoT, are just limited aspects of it. In fact as I showed separately, if the cloud is to scale, mobile/IoT needs to take on a more fat-client approach - anyone remember what I wrote about Shannon's Limit over 4 years ago? Mobile, which really means developing applications for phones that tend to rely upon backend services, is a specific implementation of IoT, which really means developing applications for a range of devices that tend to rely upon backend services (ok, with some gateway technologies in there for good measure.) See what I mean?
If you follow that assertion that everything we need to do going forward is some aspect of ubiquitous computing, then it follows from what we discussed earlier that the new stack approach of core services, Containers, management etc. all come into play and across a variety of different languages and frameworks. Whether you're developing enterprise applications for mobile devices, clouds, involving sensors, or traditional mainframes, you need a stack that is mature, rich, scalable, reliable, trustworthy and open. The Red Hat stack, which has evolved over the last decade and is continuing to evolve, is the only one that matches all of the requirements!
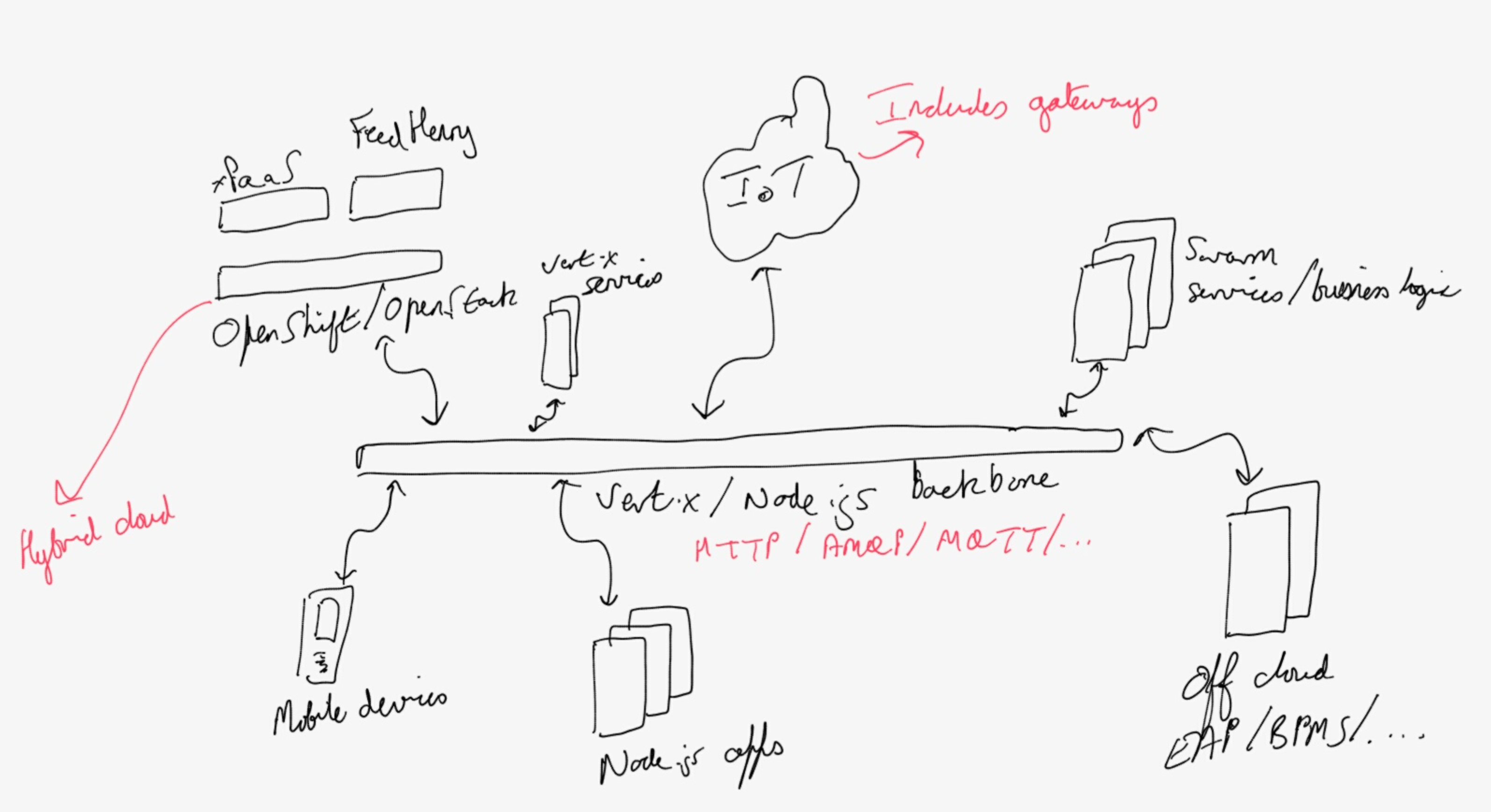
Below is a hand-drawn outline of where I see these things going. Apologies that it's not a nice block diagram and for my handwriting
 5.
5.
 4.
4.