JAX-RS 2.0 : Server side Processing Pipeline | Thinking in Java EE (at least trying to!): "The inspiration for this post was the Processing Pipeline section in the JAX-RS 2.0 specification doc (Appendix C). I like it because of the fact that it provides a nice snapshot of all the modules in JAX-RS – in the form of a ready to gulp capsule !"
'via Blog this'
Showing posts with label javaee. Show all posts
Showing posts with label javaee. Show all posts
Tuesday, 3 May 2016
Saturday, 19 March 2016
Container Tidbits: When Should I Break My Application into Multiple Containers? – Red Hat Enterprise Linux Blog
Container Tidbits: When Should I Break My Application into Multiple Containers? – Red Hat Enterprise Linux Blog:
There is a lot of confusion around which pieces of your application you should break into multiple containers and why. I recently responded to this thread on the Docker user mailing list which led me to writing today’s post. In this post I plan to examine an imaginary Java application that historically ran on a single Tomcat server and to explain why I would break it apart into separate containers. In an attempt to make things interesting – I will also aim to justify this action (i.e. breaking the application into separate containers) with data and (engineering) logic… as opposed to simply stating that “there is a principle” and that one must adhere to it all of the time.
Let’s take an example Java application made up of the following two components:
As mentioned, this application historically ran in a single Tomcat server and the two components were communicating over a REST-based API… so the question becomes:
Should I break this application into multiple containers?
Yes. I believe this application should be decomposed into two different Docker containers… but only after careful consideration.
There is a lot of confusion around which pieces of your application you should break into multiple containers and why. I recently responded to this thread on the Docker user mailing list which led me to writing today’s post. In this post I plan to examine an imaginary Java application that historically ran on a single Tomcat server and to explain why I would break it apart into separate containers. In an attempt to make things interesting – I will also aim to justify this action (i.e. breaking the application into separate containers) with data and (engineering) logic… as opposed to simply stating that “there is a principle” and that one must adhere to it all of the time.
Let’s take an example Java application made up of the following two components:
- A front-end application built on the Struts Web Framework
- A back-end REST API server built on Java EE
As mentioned, this application historically ran in a single Tomcat server and the two components were communicating over a REST-based API… so the question becomes:
Should I break this application into multiple containers?
Yes. I believe this application should be decomposed into two different Docker containers… but only after careful consideration.
Monday, 11 January 2016
Microservices links
The Power, Patterns, and Pains of Microservices
A full-throated advocate of winning knows that the one constant in business is change. The winners in today's ecosystem learned this early and quickly.
One such example is Amazon. They realized early on that they were spending entirely too much time specifying and clarifying servers and infrastructure with operations instead of deploying working software. They collapsed the divide and created what we now know as Amazon Web Services (AWS). AWS provides a set of well-known primitives, a cloud , that any developer can use to deploy software faster. Indeed, the crux of the DevOps movement is about breaking down the invisible wall between what we knew as developers and operations to remove the cost of this back-and-forth.
Another company that realized this is Netflix. They realized that while their developers were using TDD and agile methodologies, work spent far too long in queue, flowing from isolated workstations—product management, UX, developers, QA, various admins, etc.—until finally it was deployed into production. While each workstation may have processed its work efficiently, the clock time associated with all the queueing meant that it could sometimes be weeks (or, gulp , more!) to get software into production.
In 2009, Netflix moved to what they described as the cloud-native architecture . They decomposed their applications and teams in terms of features; small (small enough to be fed with two pizza-boxes !) collocated teams of product managers, UX, developers, administrators, etc., tasked with delivering one feature or one independently useful product. Because each team delivered a set of free-standing services and applications, individual teams could iterate and deliver as their use cases and business drivers required, independently of each other. What were in-process method invocations became independently deployed network services.
Microservices, done correctly, hack Conway's law and refactor organizations to optimize for the continuous and safe delivery of small, independently useful software to customers. Independently deployed software can be more readily scaled at runtime. Independently deployed software formalizes service boundaries and domain models; domain models are forced to be internally consistent, something Dr. Eric Evans refers to as a bounded context in his epic tome, Domain Driven Design .
Independent deployability implies agility but also implies complexity; as soon as network hops are involved you have a distributed systems problem!
Monday, 16 November 2015
Mark Little: Is Java EE Still Relevant?
https://developer.jboss.org/blogs/mark.little/2015/11/15/is-java-ee-still-relevant
I had a great time at JavaOne this year and Red Hat had a fantastic showing, with many sessions at the event, many more booth sessions (which were packed out as usual) and of course I made a brief appearance during the kickoff keynote. There had been a lot of interest in this event due to some recent events and rumours about what Oracle would or wouldn't say, specifically about the future of Java EE. This was even a topic of conversation during the JCP EC face-to-face meeting preceding JavaOne. But nothing much really happened and life, it seemed, would go on as usual. However, there was still a lot of discussion during several sessions and through the usual chatter on the floors or parties about the relevancy of Java EE these days.
But let's face it, this isn't a question that is only being asked in 2015; I've been involved in enterprise Java since before it was called J2EE and within a few years of bring created people were asking the same question. As I've mentioned many times over the past few years, people have asked the question when Web Services came along, then REST, PaaS/Cloud, mobile and now IoT. Each time the concept of middleware has evolved and Java EE, and its associated implementations, with it. People get hung up on the concept of Java EE and application servers as bloated, monolithic entities without actually looking at the reality of today's implementations (well, at least one). However, I'm not here to repeat what I've said time and time again(remember this from 2011?), most recently at HPTS 2015. Approaches such as WildFly Swarm and the massive interest it has seen, show that there's still a lot of interest. And I've already suggested how Java EE can fit into the next generation platforms.
Rather than revisit this question, which I think I've answered sufficiently, I wanted to link to Ian's entry on the JavaOne session he did, which I attended. It's always good to hear from someone else on the topic, though I'm sure some will argue he's not objective about this and neither am I. If you're still not convinced, think of the core capabilities within any Java EE application server, such as transactions, messaging, security, cacheing etc; services/capabilities that are needed way beyond Java and Java EE, pre-dating Java by decades and used together or independently in many applications. You can consider Java EE as a way of packaging these things together into a convenient bundle, where they are guaranteed to work well together or independently, and in most cases you probably don't even know they're there. Over the years, before Java was created and way beyond when it is just a mention in history books, that packaging will change but you'll still have something recognisable within middleware implementations, perhaps not co-locating services, perhaps not all implemented in the same language etc. And your future applications will probably not be able to tell the difference or know they're there ... again.
So whilst I think the original question is an important one to ask, I think a much better question is "Where should I use the core capabilities within Java EE?" And if you've got a suitably flexible and agile application server implementation, your application won't need to care that Java EE is, or is not, under the covers providing the desired dependability and reliability.
Of course microservices are the future. Ok, maybe there was a hint of sarcasm in that last sentences! Microservices have a role to play, just as SOA does (yes, I still believe the two are closely tied). There is some truth in there though: more streamlined, agile and dedicated services will be the basis of future application development, whether using (immutable) containers such as Docker or just the standard JVM, perhaps with fatjars. However, anyone who believes that the future of software (middleware) will appear instantaneously has obviously not looked back at other transitions, such as bespoke-to-CORBA or CORBA-to-J2EE. These things take time and evolution rather than revolution is the natural approach. Even if you've not been involved in middleware there are similar examples elsewhere in our industry: COBOL really is still in deployment today! Look at the interest we have around Blacktie!
Therefore, the future will evolve. Yes people will want to develop new applications (so called greenfield sites) using the latest and greatest framework or stack. But they'll also want to integrate with existing business logic and services written in a variety of present day technologies. So there'll still be Java EE application servers (e.g., EAP) with business logic within them, some of it legacy, some written from scratch today and into the future, despite what some may believe.
I believe that due to the fact Java EE has been the dominant non-Microsoft development and deployment platform for well over a decade, there are so many developers out there who are comfortable with it. Yes some may complain about the apparent bloat of implementations, but the reality is that it's still very easy to develop against and use from a variety of different programming languages. That's why the evolution towards any new paradigm is going to be heavily influenced by it, if not driven directly by those developers. So yes, I believe that microservices and Java EE go hand in hand for a large percentage of developers. Approaches such as WildFly-Swarm offer precisely what I'm describing: a comfortable entry point for developers and even existing applications, yet the power to move to a more flexible DevOps driven paradigm. WildFly, when used correctly, offers a mature and easy to use platform that has a minimal footprint and faster boot times than the most popular web servers around! And don't forget that Swarm builds on WildFly so we immediately get the maturity of implementations(s) from it.
However, this mad rush towards microservices, trimming of application servers, creation of applications from fatjars etc. needs to be approached with caution. Our industry is renowned for offering panaceas to problems that require throwing away all we've done before and relearning all of those hard earned lesson! We've got to break that cycle and in Red Hat we've got the pieces to do so: with so many open source projects out there purporting to be right for enterprise applications and new ones springing into life almost on a daily basis, it's easy to understand why people believe every new project is good enough for their requirements. Although I believe open source is a superior development methodology, it takes time and effort to build enterprise-ready components such as transaction servers, messaging brokers, etc. They don't just spring into life ready formed and fully capable. "Good enough" is rarely sufficient for enterprises. It's the edge cases like management, reliability, recoverability, scalability and bullet proof security that are hard to do and get right, yet it's precisely those edge cases that matter time and again. Through core development or acquisition, we've built up a stack that is mature and capable. Whether deployed as a stack or individual pieces, it's what we should be building the next generation of middleware solutions upon. A strong base exists today and we need to reuse as much of that as possible rather than rewrite from scratch in some new popular programming language.
Now as I hinted above, maybe we don't package our future stack or platform in quite the same way as we do today. Microservices offers an approach that is in line with the kinds of trimming we've been seeing anyway. Bundling individual components from the application server as easily deployed (container based) services that can then be exposed to other programming languages, frameworks, solutions etc. is definitely part of the overall solution space. Those core services, such as transactions or storage, could be deployed as individual services or, as is more typical with something like Swarm, deployed with the business logic that uses them. I keep coming back to the JBossEverywhere initiative we had a few years ago - ahead of its time!
Ok so we've looked to microservices and how Java EE fits in. But that can't be the entire answer - and it isn't. As I've mentioned before, at least for a very important set of applications and use cases the future is reactive and event driven. Now that could mean Node.js but just as likely in the Java world it probably means Vert.x. Note, given that many of the Java EE APIs aren't reactive or asynchronous in nature then we'll need to evolve them if we wish to tie them in to Vert.x and I do think we need to do that. Whilst some people will want to develop their applications and microservices in Vert.x from scratch, others will want to tie in legacy systems or have access to some of the core services I mention earlier. I see Vert.x as the ideal backbone or glue that brings all of these things together. The mature core services that we've got are precisely the sorts of things that enterprise developers will need for their applications as they grow in complexity - and let's face it, eventually many applications are going to need security, transactions, high performance messaging etc.
In the Java world the unit of containerisation is essentially the JVM. However, most Java developers realise that unless you ship a farjar, which contains everything you need to run your application/service, it's often typical to find that changes in third-party jars downloaded at deployment time can result in the application or service failing to run first time. This is where operating system containers, such as Docker, really come into their own. The ability to create a deployment unit which runs first time and every time is crucial! Container orchestration technologies, such as Kubernetes, are likewise important if you want to deploy services (via Containers) which are highly available, load balanced etc. Therefore, hopefully it's not too difficult to see where Containers will fit into the future architecture - not mandatory by any means, but definitely a piece of the puzzle which should be considered from the outset.
The combination of OpenShift for Container deployment and management, with Fabric8 for developer experience with CI and CD, provides a compelling hybrid cloud environment, especially once you consider all of the JBoss/Fuse middleware integrated, i.e., xPaaS. As I've mentioned before though, xPaaS isn't about simply adding the middleware products to OpenShift; we're also going to make them much more cloud-aware/cloud-enabled. This has a number of implications, but the one I want to mention specifically is that the core capabilities will be made available to developers in a more cloud-natural manner, e.g., users who want reliable messaging won't need to understand the various intricacies of JMS to use A-MQ and in fact won't even have to know A-MQ is working under the covers. And yes, for those of you still paying attention, those core capabilities I mentioned are precisely the same core services we covered earlier on. See the connection?
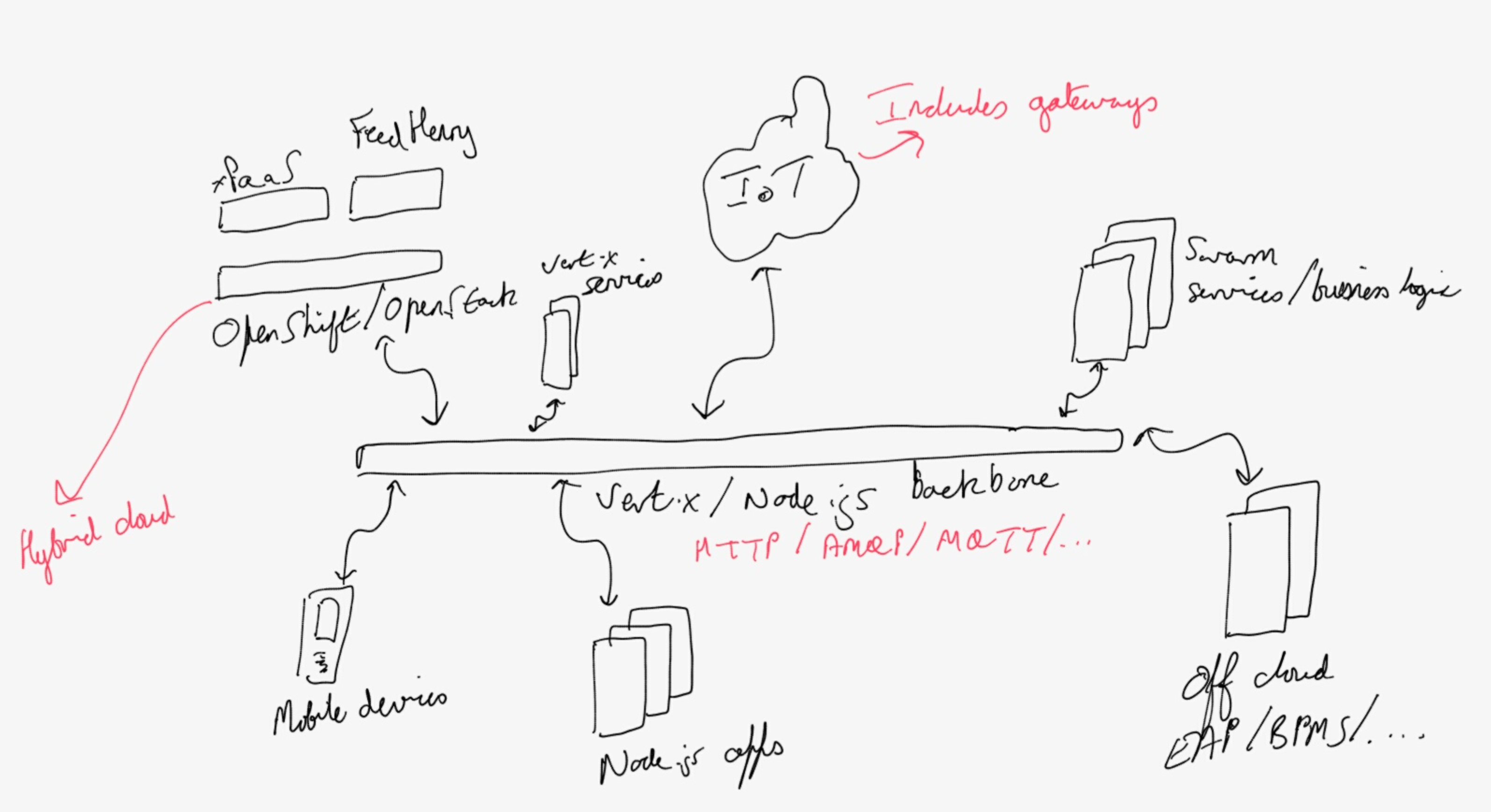
Up to this point we've really been playing in the traditional enterprise deployment arena: clients, middle tiers and servers. The cloud comes into play here at the back tier (servers), but what about mobile, IoT and ubiquitous computing? I've discussed this a few times before so won't repeat much here except that I think everything we've discussed so far has immediate applicability for ubiquitous computing and that mobile, as well as IoT, are just limited aspects of it. In fact as I showed separately, if the cloud is to scale, mobile/IoT needs to take on a more fat-client approach - anyone remember what I wrote about Shannon's Limit over 4 years ago? Mobile, which really means developing applications for phones that tend to rely upon backend services, is a specific implementation of IoT, which really means developing applications for a range of devices that tend to rely upon backend services (ok, with some gateway technologies in there for good measure.) See what I mean?
If you follow that assertion that everything we need to do going forward is some aspect of ubiquitous computing, then it follows from what we discussed earlier that the new stack approach of core services, Containers, management etc. all come into play and across a variety of different languages and frameworks. Whether you're developing enterprise applications for mobile devices, clouds, involving sensors, or traditional mainframes, you need a stack that is mature, rich, scalable, reliable, trustworthy and open. The Red Hat stack, which has evolved over the last decade and is continuing to evolve, is the only one that matches all of the requirements!
Below is a hand-drawn outline of where I see these things going. Apologies that it's not a nice block diagram and for my handwriting
Monday, 2 November 2015
J2EE Application / CDI / JCache / Hazelcast
2015 JavaOne EJB/CDI Alignment
https://hazelcast.com/resources/cluster-application-using-cdi-jcache/
You created a Java EE application using a REST front-end on top of relational database using JPA. Now you need to make it highly available and scalable across a large number of machines.
This webinar will start with a simple JAX-RS/JPA application. We will turn this standard Java EE application, step by step, into a fully clustered application using a CDI extension and producers to integrate Hazelcast, as a JCache provider. To do that we will study the data model and how to persist it efficiently.
http://www.slideshare.net/Hazelcast/j-cache-cdi-1
https://hazelcast.com/resources/cluster-application-using-cdi-jcache/
You created a Java EE application using a REST front-end on top of relational database using JPA. Now you need to make it highly available and scalable across a large number of machines.
This webinar will start with a simple JAX-RS/JPA application. We will turn this standard Java EE application, step by step, into a fully clustered application using a CDI extension and producers to integrate Hazelcast, as a JCache provider. To do that we will study the data model and how to persist it efficiently.
http://www.slideshare.net/Hazelcast/j-cache-cdi-1
Angula 1 / Angular 2 (+ Typescript)
Introducing AngularJS to Java Developers

Angular 2 versus React: There Will Be Blood
Ext JS, YUI, and Dojo represent feature-complete frameworks. AngularJS, Backbone.js, and Ember are examples of lightweight frameworks. After years of experimenting with different frameworks and libraries we decided to stick with hugely popular AngularJS by Google.
I work in a Java shop, and one of my responsibilities is to create an conduct trainings (both internal and external). Several years ago I started to work with our engineers on the curriculum introducing AngularJS to an enterprise Java developer.
The learning curve of AngularJS is not too steep for Java developers, who understand the concept of containers, dependency injections, callbacks. They must become proficient with JavaScript with its functions, closures and other good stuff.
But equally important is to be familiar with todays tooling of a productive Web developer. Here’s a short list of tools that JavaScript developers use today:
- npm – node package manager used for installing and managing development tools
- yeoman – a scaffolding tool used to generate the initial structure of an application
- bower – package manager for application dependencies
- grunt – a build automation tool
- A JavaScript testing framework
The next decision to make is how to communicate with the Java backend. Forget about JSP, servlets, and JSFs. Preparing HTML in your Java code is out of fashion. A Java server exchanges the JSON-formatted data with a single-page HTML/JavaScript front end, which use either AJAX techniques (old) or WebSocket protocol (new).
On the Java side we like to use such tried and true technologies as RESTful Web service and Java Messaging API.
When we hire a AngularJS/Java developer, we expect him to be familiar with at least 90% of all the above buzzwords. Finding such skilled software engineers may be difficult, so we’ve created a training program to prepare such a person.
By now, we’ve taught and fine-tuned this training class multiple times. The latest online version of this class consists of seven weekly training sessions (3.5 hours each) and seven consultations (from 30 to 60 min each). Programmers learn and gradually apply all of the above tools and techniques while working on the Online Auction application that has the following architecture:

We have a great feedback from people who have completed this training. But everyone says it’s challenging. And it should be. Back in the nineties a person who knew one of the programming languages plus SQL could relatively easy get a well paid job. Not anymore.
Monday, 27 July 2015
Docker and Virtualisation links
Docker for Java Developers: How to sandbox your app in a clean environment
Continuous Delivery with Docker Containers and Java EE
A Practical Introduction to Docker Container Terminology
ANNOUNCING DOCKER TOOLBOX
Docker cheat sheet
Why I love Docker
In my view Docker will enable the IT industry to adopt to DevOps and Microservices not by being a tool, but rather being a technology that fundamentally changes how we manage IT services. The practical difference is that we can now life-cycle manage everything isolated. If one application needs a new version of a JVM or PHP library they can safely upgrade without affecting other containerized applications. This enforces the organization to embrace DevOps culture and processes.
Docker also enables us to create small independent deployments, which is the foundation of Microservices architecture. This does however add another dimension to the problem, where we have to manage service dependencies. I’ll talk more about Microservers and how to manage remote dependencies in later blogs.
So to summon up, why I love Docker is not only that it’s easy to use, gives me high density and isolation, the main reason to me is that it’s going to change how we operate and manage applications.
Wednesday, 10 June 2015
James Ward: Java EE: Comparing Application Deployment: 2005 vs. 2015
James Ward: Java EE: Comparing Application Deployment: 2005 vs. 2015
Java Doesn’t Suck – You’re Just Using it Wrong
Refactoring to Microservices
2005 = Multi-App Containers / App Servers / Monolithic Apps
2015 = Microservices / Docker Containers / Containerless AppsBack in 2005 many of us worked on projects that resulted in a WAR file – a zip file containing a Java web application and its library dependencies. That web application would be deployed alongside other web applications into a single app server sometimes called a “container” because it contained and ran one or more applications. The app server provided a bunch of common services to the web apps like an HTTP server, a service directory, and shared libraries. Unfortunately deploying multiple apps in a single container created high friction for scaling, deployment, and resource usage. App servers were supposed to isolate an app from its underlying system dependencies in order to avoid “it works on my machine” problems but things often didn’t work that smoothly due to differing system dependencies and configuration that lived outside of the app server / container.In 2015 apps are being deployed as self-contained units, meaning the app includes everything it needs to run on top of a standard set of system dependencies. The granularity of the self-contained unit differs depending on the deployment paradigm. In the Java / JVM world a “containerless” app is a zip file that includes everything the app needs on top of the JVM. Most modern JVM frameworks have switched to this containerless approach including Play Framework, Dropwizard, and Spring Boot. A few years ago I wrote in more detail about how app servers are fading away in the move from monolithic middleware to microservices and cloud services.For a more complete and portable self-contained unit, system-level container technologies like Docker and LXC bundle the app with its system dependencies. Instead of deploying a bunch of apps into a single container, a single app is added to a Docker image and deployed on one or more servers. On Heroku a “Slug” file is similar to a Docker image.Microservices play a role in this new landscape because deployment across microservices is independent, whereas with traditional app servers individual app deployment often involved restarting the whole server. This was one reason for the snail’s pace of deployment in enterprises – deployments were incredibly risky and had to be coordinated months in advance across numerous teams. Hot deployment was a promise that was never realized for production apps. Microservices enable individual teams to deploy at will and as often as they want. Microservices require the ability to quickly provision, deploy, and scale services which may have only a single responsibility. These requirements fit well with the infrastructure provided by containerless apps running on Docker(ish) Containers.2005 = Manual Deployment
2015 = Continuous Delivery / Continuous DeploymentThe app servers of 2005 that ran multiple monolithic apps combined with manual load balancer configurations made application upgrades risky and painful so deployments were usually done sparingly in designated maintenance windows. Back then it was pretty much unheard of to have a deployment pipeline that fully automated delivery from an SCM to production.Today Continuous Delivery and Continuous Deployment enable developers to get code to staging and production sometimes as often as tens or even hundreds of times a day. Scalable deployment pipelines range from the simple “git push heroku master” to a more risk averse pipeline that includes pull requests, Continuous Integration, staging auto-deployment, manual promotion to production, and possibly Canary Releases & Feature Flags. These pipelines enable organizations to move fast and distribute risk across many small releases.In order for Continuous Delivery to work well there are a few ancillary requirements:
- Release rollbacks must be instant and easy because sometimes things are going to break and getting back to a working state quickly must be painless and fast.
- Patch releases must be able to make it from SCM to production (through a continuous delivery pipeline) in minutes.
- Load balancers must be able to handle automatic switching between releases.
- Database schema changes should be decoupled from app releases otherwise releases and rollbacks can be blocked.
- App-tier servers should be stateless with state living in external data stores otherwise state will be frequently lost and/or inconsistent.
2005 = Persistent Servers / “Pray it never goes down”
2015 = Immutable Infrastructure / Ephemeral ServersWhen a server crashed in 2005 stuff usually broke. Some used session replication and server affinity but sessions were lost and bringing up new instances usually took quite a bit of manual work. Often changes were made to production systems via SSH making it difficult to accurately reproduce a production environment. Logging was usually done to local disk making it hard to see what was going on across servers and load balancers.Servers in 2015 are disposable, immutable, and ephemeral forcing us to plan for them to go down. Tools like Netflix’s Chaos Monkey randomly shut down servers to make sure we are preparing for crashes. Load balancers and management backplanes work together to start and stop new instances in an instant enabling rapid scaling both up and down. By being immutable we can no longer fix production issues by SSHing into a server but now environments are easily reproducible. Logging services route STDOUT to an external service enabling us to see the log stream in real time, across the whole system.2005 = Ops Team
2015 = DevOpsIn 2005 there was a team that would take your WAR file (or other deployable artifact) and be responsible for deploying it, managing it, and monitoring it. This was nice because developers didn’t have to wear pagers but ultimately the Ops team often couldn’t do much if there was a production issue at 3am. The biggest downside of this was that Ops became all about risk mitigation causing a tremendous slowdown in software delivery.Modern technical organizations of all sizes are ditching the Ops velocity killer and making developers responsible for the stuff they put into production. Services like New Relic, VictorOps, and Slack help developers stay on top of their new operational responsibilities. The DevOps culture also directly incentivizes devs not to deploy things that will end up waking them or a team member up at 3am. A core indicator of a DevOps culture is whether a new team member can get code to production on their first day. Doing that one thing right means doing so many other things right, like:
- 3 Step Dev Setup: Provision the system, Checkout the code, and Run the App
- SCM / Team Review (e.g. GitHub Flow)
- Continuous Integration & Continuous Deployment / Delivery
- Monitoring and Notifications
DevOps can sound very scary to traditional enterprise developers like myself. But from experience I can attest that wearing a pager (metaphorically) and assuming the direct risk of my deployments has made me a much better developer. The quality of my code and my feelings of fulfillment have increased with my new level of ownership over what is in production.Learn MoreI’ve just touched the surface of many of the deployment changes over the past 10 years but hopefully you now have a better understanding of some of the terminology you might be hearing at conferences and on blogs. For more details on these and related topics, check out The Twelve-Factor App and my blog Java Doesn’t Suck – You’re Just Using it Wrong. Let me know what you think!
Java Doesn’t Suck – You’re Just Using it Wrong
Refactoring to Microservices
Thursday, 16 April 2015
zeroturnaround.com: Architecting Large Enterprise Java Projects with Markus Eisele
http://zeroturnaround.com/rebellabs/architecting-large-enterprise-java-projects-by-markus-eisele/
Developers built a lot of applications like that some time ago and even present day! These applications are still working and need maintenance. So we see them sometimes and call them legacy. They tend to have a release cycle of once or twice a year, depend on a proprietary application server environment and most importantly have a single database schema for all data. Naturally, you cannot move very fast with such a beast on your shoulders and must have a large team and QA department even just to maintain it.
The next step in the architecture design was the Enterprise Service Bus age. Understanding that changes have to be incorporated into even the oldest and the most legacy applications. We (Java developers) started breaking the huge apps into smaller ones. The biggest challenge was to integrate it all together, so the service bus seemed the best solution.
The change wasn’t that big for the operations teams, as they still have everything under their control and centralized, although it was a much more flexible approach. However, the same centralization that adds value, creates a raft of problems that the engineering team had to solve: most importantly challenges with testing and the single point of failure (SPOF).
We’re now we’re moving even further away from the monolithic apps and towards the trendingbuzzword of Microservices.
Then there’s a number of patterns you can use to organise the communication between your microservices, like the Aggregator or the Chain.
General Java/JavaEE links
Java 8 Stream Tutorial
How to use flatMap() in Java 8 - Stream Example Tutorial
Continuous Delivery with Docker Containers and Java EE
Microservices, DevOps and PaaS - The Impact on Modern Java EE Architecture
What Would ESBs Look Like If They Were Done Today?
EJB and CDI - Alignment and Strategy
Upgrading to Java 8 at Scale
Productive Java EE 7 on Java 8 At Commerzbank
Basics of scaling Java EE applications
Design pattern samples in Java
Java 8’s Method References Put Further Restrictions on Overloading
Dismantling invokedynamic
Javascript for Java Developers
A curated list of awesome Java frameworks, libraries and software
Java 8 Streams cheat sheet
How to use flatMap() in Java 8 - Stream Example Tutorial
Continuous Delivery with Docker Containers and Java EE
Microservices, DevOps and PaaS - The Impact on Modern Java EE Architecture
What Would ESBs Look Like If They Were Done Today?
EJB and CDI - Alignment and Strategy
Upgrading to Java 8 at Scale
Productive Java EE 7 on Java 8 At Commerzbank
Basics of scaling Java EE applications
Design pattern samples in Java
Java 8’s Method References Put Further Restrictions on Overloading
Dismantling invokedynamic
Javascript for Java Developers
Attila Szegedi (@asm) - Nashorn and JVM Performance @jfokus http://t.co/2gKbe6px1w
— NightHacking (@_nighthacking) February 5, 2015
Iron Clad Java: 'a master class in secure Java design & coding, written for DEVs by guys who truly know their shit.’ http://t.co/eCrvWt4Lsv
— Jeremiah Grossman (@jeremiahg) January 29, 2015
I'm crying. -XX:SelfDestructTimer=1. It works.
— Anton Arhipov (@antonarhipov) January 20, 2015
Manipulating JARs, WARs, and EARs on the Command Line http://t.co/tQAS1OTR6r #Java
— Markus Eisele (@myfear) November 30, 2014
Work with JVM? Never miss a @BrianGoetz talk: https://t.co/IKL11Pb3BB
— Dean Wampler (@deanwampler) November 24, 2014
most j2ee patterns are useless today: @AdamBien: How To Deal With J2EE and Design Patterns http://t.co/womnGpxw98
— martin (@c4n70r) August 21, 2014
Dependency Injection, Annotations, and why #Java is Better Than you Think it is http://t.co/TKQCaKiRJr /via @cmoulliard
— Markus Eisele (@myfear) August 19, 2014
"Loose coupling with Context and Dependency Injection" http://t.co/5f4xJvaPX5 #CDI #JavaEE
— Markus Eisele (@myfear) August 1, 2014
"Some facts about Stateless EJB beans" from #JavaEESquade : http://t.co/r9l0fpdsYu
— Antonio Goncalves (@agoncal) July 17, 2014
A curated list of awesome Java frameworks, libraries and software
Java 8 Streams cheat sheet
Tuesday, 30 December 2014
vladmihalcea.com: A BEGINNER’S GUIDE TO TRANSACTION ISOLATION LEVELS IN ENTERPRISE JAVA
http://vladmihalcea.com/2014/12/23/a-beginners-guide-to-transaction-isolation-levels-in-enterprise-java/
A relational database strong consistency model is based on ACID transaction properties. In this post we are going to unravel the reasons behind using different transaction isolation levels and various configuration patterns for both resource local and JTA transactions.
Subscribe to:
Posts (Atom)