The Power, Patterns, and Pains of Microservices
A full-throated advocate of winning knows that the one constant in business is change. The winners in today's ecosystem learned this early and quickly.
One such example is Amazon. They realized early on that they were spending entirely too much time specifying and clarifying servers and infrastructure with operations instead of deploying working software. They collapsed the divide and created what we now know as Amazon Web Services (AWS). AWS provides a set of well-known primitives, a cloud , that any developer can use to deploy software faster. Indeed, the crux of the DevOps movement is about breaking down the invisible wall between what we knew as developers and operations to remove the cost of this back-and-forth.
Another company that realized this is Netflix. They realized that while their developers were using TDD and agile methodologies, work spent far too long in queue, flowing from isolated workstations—product management, UX, developers, QA, various admins, etc.—until finally it was deployed into production. While each workstation may have processed its work efficiently, the clock time associated with all the queueing meant that it could sometimes be weeks (or, gulp , more!) to get software into production.
In 2009, Netflix moved to what they described as the cloud-native architecture . They decomposed their applications and teams in terms of features; small (small enough to be fed with two pizza-boxes !) collocated teams of product managers, UX, developers, administrators, etc., tasked with delivering one feature or one independently useful product. Because each team delivered a set of free-standing services and applications, individual teams could iterate and deliver as their use cases and business drivers required, independently of each other. What were in-process method invocations became independently deployed network services.
Microservices, done correctly, hack Conway's law and refactor organizations to optimize for the continuous and safe delivery of small, independently useful software to customers. Independently deployed software can be more readily scaled at runtime. Independently deployed software formalizes service boundaries and domain models; domain models are forced to be internally consistent, something Dr. Eric Evans refers to as a bounded context in his epic tome, Domain Driven Design .
Independent deployability implies agility but also implies complexity; as soon as network hops are involved you have a distributed systems problem!
Adrian Cockcroft: Microservices Can Slow Down Small Dev Shops
Sam Newman: Practical Implications of Microservices in 14 Tips
Your Lead Architect Doesn’t Really Understand Microservices
A few months ago, I was asked to review an infrastructure diagram for an application that would use a “microservices” architecture.
“I only see one database labeled here,” I said. “What are the datastores for all of the separate microservices?”
“Oh, that makes things too difficult — it’s much better with only one database,” the lead architect replied. “But we have an API layer microservice that connects all the other microservices to it.”
“What happens if the database goes down? Don’t the microservices go down? And if you need to upgrade the database server, doesn’t that impact the whole system?”
“Of course. That’s how you have to do it.”
The lead architect here had gone to several conferences that featured speakers on microservices architectures, and had read many blog posts on the topic. But fundamentally, he had no clue what the fundamental “raison d’être” of a microservices architecture is.
As well as decentralizing decisions about conceptual models, microservices also decentralize data storage decisions. While monolithic applications prefer a single logical database for persistant data, enterprises often prefer a single database across a range of applications - many of these decisions driven through vendor's commercial models around licensing. Microservices prefer letting each service manage its own database, either different instances of the same database technology, or entirely different database systems - an approach calledPolyglot Persistence. You can use polyglot persistence in a monolith, but it appears more frequently with microservices.
Decentralizing responsibility for data across microservices has implications for managing updates. The common approach to dealing with updates has been to use transactions to guarantee consistency when updating multiple resources. This approach is often used within monoliths.
Using transactions like this helps with consistency, but imposes significant temporal coupling, which is problematic across multiple services. Distributed transactions are notoriously difficult to implement and and as a consequence microservice architecturesemphasize transactionless coordination between services, with explicit recognition that consistency may only be eventual consistency and problems are dealt with by compensating operations.
Choosing to manage inconsistencies in this way is a new challenge for many development teams, but it is one that often matches business practice. Often businesses handle a degree of inconsistency in order to respond quickly to demand, while having some kind of reversal process to deal with mistakes. The trade-off is worth it as long as the cost of fixing mistakes is less than the cost of lost business under greater consistency.
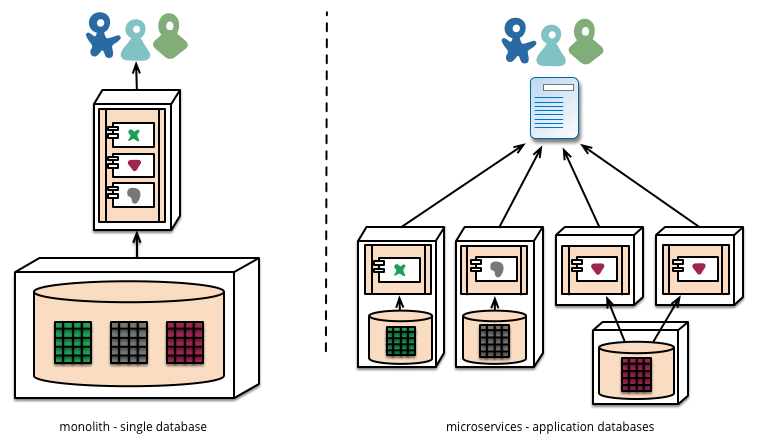
The challenges of building and deploying microservices
Increasingly microservices are being conflated with container technology, and some of the motivations behind this are valid – containers (such as Docker and rkt) appear to be great packaging mechanisms for running small, isolated and ephemeral services – but some of the motives, such as providing enforcement of good architectural principles like encapsulation, are decidedly more suspect.
Therefore, although the two technologies are decidedly separate, I’m going to assume that people are predominantly deploying microservices within some kind of container-like vehicle – perhaps a VM image, Docker container, or a Cloud Foundry Warden/Garden container. This means that you will in all likelihood require some kind of deployment fabric that acts like a platform/cluster manager, which handles scheduling and orchestration of these container-like application vehicles.
The top three open source cluster management fabrics at the moment are Apache Mesos (combined with Marathon orAurora), Google’s Kubernetes, and some flavour of Cloud Foundry (including Lattice). Other vendor-specific fabrics do exist, such as AWS’s EC2 Container Service (ECS), and they do provide quite a lot of the ‘platform’ responsibilities I mentioned above, but there is some degree of vendor lock-in. The open source solutions primarily assume you are going to ‘roll your own’ platform.
There are some notable exceptions here – Mesosphere are working on their Datacenter Operating System (DCOS), Red Hat have created the OpenShift v3 / fabric8 / Kubernetes platform, CoreOS offer the Kubernetes-based Tectonic, and Pivotal and IBM have created Cloud Foundry ecosystems with Pivotal Cloud Foundry and Bluemix respectively. Other notable attempts at creating an open microservice platform include Cisco’s Mantl (formerly known as microservice-infrastructure) and Capgemini’s Apollo, both of which are based on Apache Mesos, and leverage other open technologies such as Hashicorp’s Terraform, CoreOS’s etcd and Mesosphere’s Marathon.
Some assembly still required…
So, if you do decide to go-it alone with something like Mesos, Kubernetes or Cloud Foundry (or even if you do utilise the emerging platforms), what are some of the technical challenges you might face?
- Developer tooling – developing locally, automation of tasks, fast feedback
- Dependency management – dependent components/libraries, other services, data stores
- Deployment – infrastructure and application
- Orchestration – service discovery, phased (blue/green, canary) rollout, health-checking
- Testing – unit/integration/system, ensuring that everything plays well together
- Monitoring – all the things!
Working Locally with Microservices
The pre-pipeline (local) development process
If we look at a typical build pipeline for a monolithic application we can see that the flow of a single monolithic component is relatively easy to orchestrate. The pipeline obviously gets more complex when we are dealing with microservices, and we’ll cover this in future blog posts, but for now we will look at the pre-pipeline local development phase that will most likely involve working simultaneously with multiple dependent services.

When working with a monolithic codebase we should be able to assume that the creation and configuration of a local development machine is as least as easy to configure as a QA environment (and if it isn’t, then you should be asking why!). Local developer machine configuration tooling such as Github’s Boxen (Puppet), Pivotal’s Sprout (Chef), ormac-dev-playbook (Ansible) allow us to specify the installation of local tooling and standardise configuration, or alternatively virtualised local environments through the use of Vagrant or Docker Compose (née Fig), are relatively easy to set up for a single stack.
Within the world of microservices the tooling for these development tasks often exists at a component/service level, but things get a lot more challenging when the number (and variety) of services increases, the number of dependencies between services increases, or when a complex business workflow takes place at a higher (system) level that involves several coordinating services.
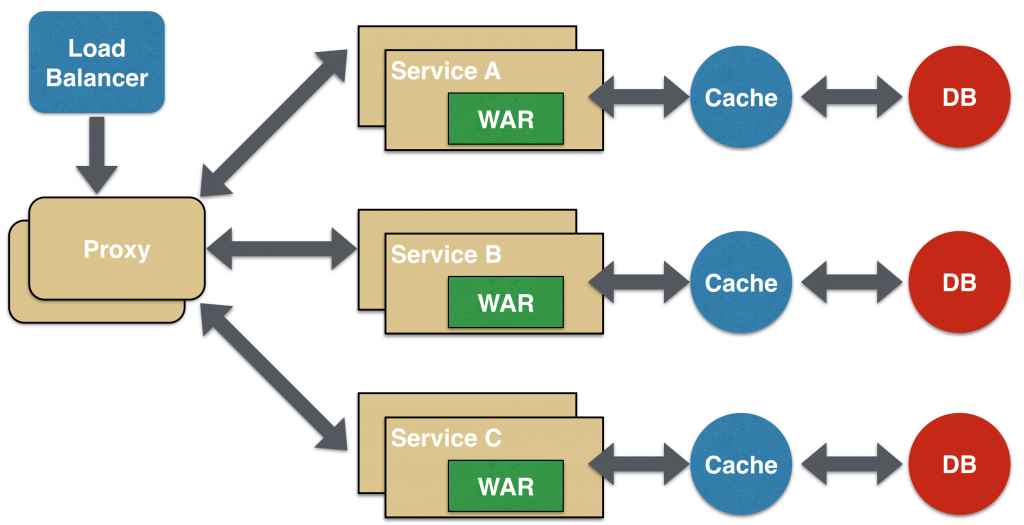
blog.arungupta.me: Microservice Design Patterns
e.g. Proxy Microservice Design Pattern
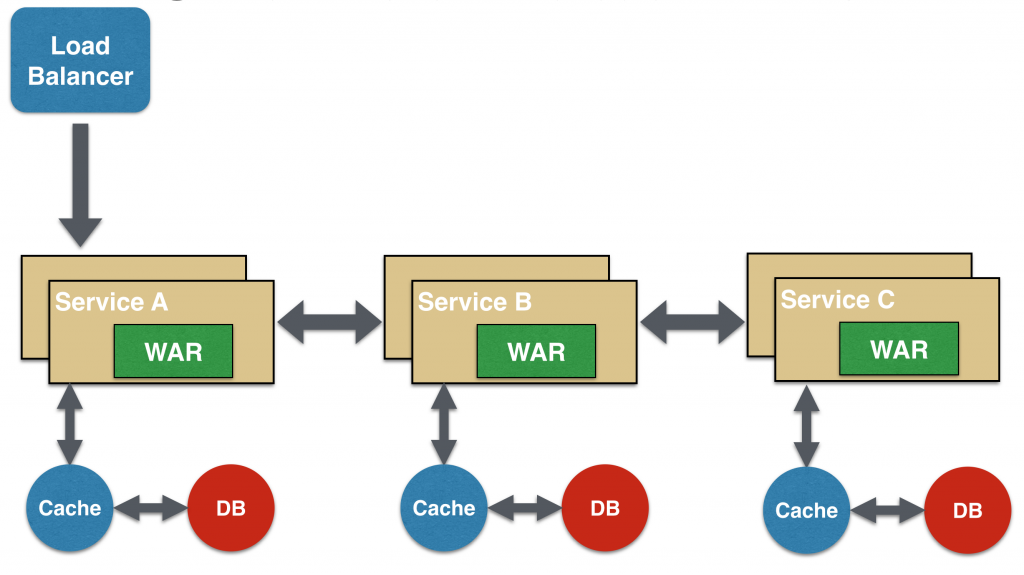
Chained Microservice Design Pattern
blog.arungupta.me: Microservices, Monoliths, and NoOps
Microservices may seem like a silver bullet that can solve significant amount of software problems. They serve a pretty good purpose but are certainly not easy. A significant operations overhead is required for these, and this article from Infoworld (Reducing technical debt with microservices) clearly points out.with microservices, some technical debt is bound to shift from dev to ops, so you’d better have a crack devops team in placeThis is very critical as now your one monolith is split across multiple microservices and they must talk to each other. Each microservice may be using a different platform, stack, persistent store and thus will have different monitoring and management requirements. Each service can then independently scale on X-axis and Z-axis. Each service can be redeployed multiple times during the day.
Refactoring may not be trivial but in the long terms this has benefits which is also highlighted in the previously quoted article from Infoworld:
Functional decomposition of a monolith is very important otherwise it becomes a distributed monolith as opposed to a microservice based application.Refactoring a big monolithic application [using microservices] can be the equivalent of a balloon payment [for reducing technical debt] … you can pay down technical debt one service at a time
infoQ Video: Rebecca Parsons on Microservices: Challenges, Benefits and Service Design
Neal Ford: Architecture is abstract until operationalized
Too many architects fail to realize that a static picture of architecture has a short shelf life. The software universe exists in a state of constant flux, it is dynamic rather than static. Architecture isn’t an equation but rather a snapshot of an ongoing process.
Continuous Delivery and the DevOps movement illustrated the pitfalls of ignoring the effort required to implement an architecture and keep it current. There is nothing wrong with modeling architecture and capturing those efforts, but the implementation is only the first step.
Architecture is abstract until operationalized. In other words, you can’t really judge the long-term viability of any architecture until you’ve not only implemented it but also upgraded it. And perhaps even enabled it to withstand unusual occurrences.
Here’s a concrete example, based on real client experiences. Architects for an airline created a services-based architecture with a canonicalCustomerservice, encapsulating everything known about customers. This is a natural instinct of software design, the DRY (Don’t Repeat Yourself) principle, Single Source of Truth, and other good (but abstract) ideas. Then, a volcano erupted in Iceland, disrupting air travel drastically. Customers of the airline flooded the support center with calls, asking if the disaster would affect their flight. And people holding tickets in unaffected parts of the world couldn’t board their planes (because, of course, ticket lookups involvedCustomer). While the architecture made logical sense, it fell over during extraordinary circumstances. While it might seem wasteful or perhaps even lead to duplication (gasp!), having multiple customer services (one to handle customer issues, one to handle boarding) would have served the business better. Only by thinking about the operational aspects of architecture can you build more robust systems, which is one of the goals of microservice architectures.
Microservice architecture is the first post-DevOps revolution architecture, highlighting the realization that architecture and DevOps must mesh, making operational concerns a first-class citizen in architectural design.
Traditionally, change is the most feared thing for software architecture. Martin Fowler wrote an article entitled Who Needs an Architect? highlighting several historical definitions of architecture, some of which say that “architecture is the set of design decisions that must be made early in a project”. Because the architectural elements present scaffolding that everything else must rely upon, changes to architecture are typically time consuming and difficult. Some portion of that difficulty is caused by ignoring the operational aspects of architecture. Microservice architectures assume constant evolutionary change, making it less expensive and error prone, even in extraordinary situations. A good example of designing for robustness comes from one of the reference microservice architectures, NetFlix. Many operations groups treat their deployments as fragile, delicate things. Netflix tries to disrupt their ecosystem with tools like the Simian Army, designed to stress their architecture in imaginative ways.
You don’t have to go all the way to an exotic microservices architecture to see benefits from this perspective shift. A good example of the empowering effects of good operational control on architecture is the continuous delivery practice of decoupling deployment from release.
One of the scariest events for traditional monoliths is Going Live, because you must make all the changes work all at once: database, code, configuration, integration, etc. If you are accustomed to this Big Bang world, a practice like continuous deployment sounds insane: how can you manage all that change all the time? The secret is to separate deployment from feature release. Feature Toggles are a common continuous delivery practice to allow in-flight feature definitions in trunk-based development. Toggle libraries like Togglz allow you to control feature exposition at runtime via a filter servlet. Thus, you can deploy a component into your ecosystem that includes toggled off code, which allows you to make sure (via monitoring) that the deployed component hasn’t had any ill effects on the ecosystem. At the selected time, you can enable the feature, continuing to monitor to make sure nothing is awry. If something does go wrong, turn the feature back off while you determine a fix. By decoupling deployment from release, we separate the operational concerns from the developers and users.
Microservices happens to be the first architecture to fully embrace DevOps, but it won’t be the last. The operational concerns of architecture will continue to impact our design and decisions, which I consider part of the maturation process for software architecture.
Jeff Sussna: Microservices, Have You Met…DevOps?
In order for microservices to work, though, ops needs a similar conceptual framework. Trying to manage an entire universe of microservices from the outside increases the scope of concern instead of reducing it. The solution is to take the word “service” seriously. Each microservice is just that: a software service. The team that builds and operates it need only worry about it and its immediate dependencies. Dependent services are customers; services upon which a given microservice depends are vendors.How do you ensure robustness, and manage failure, when you restrict your operational scope to local concerns? The reason we try to operate microservice architectures monolithically in the first place is because we think “but it all has to work”. The answer is to treat them as the complex systems they are, instead of the complicated systems they’re replacing. If each microservice is a first-class service, its dependencies are third-parties, just like Google Maps, or Twilio, or any other external service. Third-party services fail, and systems that depend on them have no choice but to design for failure.Microservices promise increased agility combined with improved quality. To achieve both goals, organizations have to shift their definition of system-level quality from stability to resilience. If they can do that, they can reflect that definition of quality in their organizational structure. Just as a SaaS company as a whole would use DevOps to deliver service quality and agility, so too each microservice would do the same.
Christian Posta: You're not going to do Microservices
Most organizations are not structured for microservices
We all hear about Conway's law, but this fact is the strongest reason why you're not going to do microservices. People win. Culture wins. Paper processes and paper structure does not win. If you have a UI team, DB team, "services" team, each specializing in its own right, you'll end up with systems that look like those tiers. There's nothing wrong with that per-se. But a tree-like structure and layers of managers above technological-grouped teams is an impediment to microservices-based teams.REST is not a silver bullet
REST is great! I like the concepts, and that for enterprises it's basically the HTTP implementation we talk about. I'm happy to get away from SOAP. HTTP and REST is understood, has great tools, networking equipment, proxies, etc are all built with it in mind...But REST is not a silver bullet.Modularizing applications is hard
How big should the service be? How deep should it be? Single responsibilities? Domain Driven Design bounded contexts, etc. This is all difficult to get right in practice. Doing it a few times and failing is the best (in my opinion) way to learn how to avoid the sharp edges, but properly modularizing your applications and your domain services is not easy.We still don't understand how to do event-based architectures
Why are we still connecting everything by RPC!?!? This one aggravates me the most that we still don't know how to do Event driven architectures correctly, and that when a "new" architectural style comes about, we relive all of the same mistakes we did with the previous. BTW.... Microservices != REST.
Microservices. No one ESB knows about every service.
This is great (no bottlenecks)
and terrible (no source of the whole truth).
— Jessica Kerr (@jessitron) January 21, 2015
Probabilistic programming code examples https://t.co/qNId8VDcU5 @startupml #NextML
— Arno Candel (@ArnoCandel) January 17, 2015
Microservices architecture: The need-to-know approach for enterprise app developers.|Fierce Wireless http://t.co/T529XbDf8u
— Ericsson Research (@EricssonLabs) November 28, 2014
Practical Probabilistic Programming (http://t.co/NpecSd6MIP) looks interesting. Uses a Scala toolkit called Figaro, https://t.co/r2TRM6jUFm
— Dean Wampler (@deanwampler) August 11, 2014
Ben Morris: How big is a microservice?
It’s important to stress how important refactoring is here. You have to start somewhere and the more your build the more obvious it becomes where the boundaries between your services should be. Whenever you encounter something that looks like it should be separate then you can spin it out as a new service.
Domain Driven Design (DDD) does provide a number of helpful tools for grappling with the kind of complexity inherent in designing distributed systems. It is almost impossible to describe a large and complex domain in a single mode, so DDD breaks this down into a series of bounded contexts. Each of these bounded contexts has an explicit boundary and contains a unified and consistent internal model.
A bounded context is characterised by what is called a ubiquitous language where every term has a precise and unambiguous definition. This tends to set a limit on the size of a bounded context as the more you enlarge it, the more ambiguity creeps in.
In my view a single deployable service should be no bigger than a bounded context, but no smaller than an aggregate. I would also suggest that it’s better to start with relatively broad service boundaries to begin with, refactoring to smaller ones as time goes on.
Perhaps “micro” is a misleading prefix here. These are not necessarily “small” as in “little”. These are services in the classic SOA mould, except created with more of an agile mind-set including lightweight infrastructure, decentralized governance and greater emphasis on automation. Perhaps it’s these more agile aspects of microservice design that distinguishes them as opposed to size.
Microservices Hangover: When Your Architecture Demands an Alka Seltzer
Voxxed: I think this is a scenario a lot of shops face, particularly if you’re not that big – you’ve got that crux between, “This could really help us down the line,” and also, you’ve got your day to day business.
Kelly: Right, and that’s the thing. And like I said, because we already had a reasonably effective way of scaling and deploying our services into discrete clusters, it got us some of the benefit of microservices, without a lot of the pain of having to extract things or to worry and to handle with really complicated and distributed transactions, which is one of the main downfalls of the microservice architecture.
Unless you have a really strong sense of how distributed transactions work…how to recover them…and what does it mean if you have six services in sequence and service two and four fail? Do you roll back, do you roll forward, do you care at all? It’s very difficult to reason about a lot of that stuff without spending a lot of time up front. And not having to worry about that as much enables us to ship product and features a lot faster.
Voxxed: So if someone else is dealing with these distributed transactions and they’re thinking about taking the jump into microservices, would your advice be, “Run, run away!”?
Kelly: No, it wouldn’t. I think it’s definitely one of those things where you need to take a look at your product in your company and decide; is this something we need to do? Is this something we can do? Do we properly understand how distributed transactions work? Do we know how to scale services over the network?
It’s definitely not as easy as all the really cool blog posts made it sound! But, I wouldn’t say it’s a bad thing. It’s definitely an architecture that makes a lot of sense for certain use cases.
I hate to give vague non-answers, but you really do need to take a look at what you’re doing and your engineering team and the talent that you have there and decide, is it more important to break things into discrete little composable services and do you guys understand how to reason about that? Or is it better to keep them under one house where they can all talk together, and focus more on code quality issues where you can maintain internal consistencies so that you don’t have dependencies that are reaching across into each other, or are nested or circular in any capacity, and to focus more on internal code architecture, as opposed to external service architecture….
I think a lot of people may have seen the microservices approach as, “Oh, we’re going to carve out our code into discrete services, and along the way, we’re going to clean it up too…We’re going to take care of tech debt, and do all this new shiny stuff.”
But what they realised is that all they did was add more tech debt to their stack, when you could have just focused on internal code cleanup and consistency – at least, that’s the way I’ve seen a lot of this stuff going with some of the blog posts that I’ve read, both before, as the microservices “boom” took off, and then after when people were waking up and realising, “This wasn’t the magical cure all I thought it was! We still have all these problems…we did
Microservices and Teams at Amazon
Microservices and Teams at Amazon
Munns, Business Development Manager for DevOps at Amazon, refers to Wikipedia for adefinition of microservices but also states four constraints:
- Single-purpose.
- Connect only through APIs.
- Connect over HTTPS.
- Largely black boxes to each other.
When comparing microservices with SOA Munns notes some distinctive differences
| Microservices | SOA |
|---|---|
|
|
The well-known term two pizza teams for describing size of teams at Amazon are actually called Service teams and own the “primitives” they build, which includes product planning, development work and operational and client support work. They have full ownership and accountability and are also responsible for the day-to-day operations and maintenance, known as you build it, you run it. This means that quality assurance (QA), being on call and operations all exists within a service team, but Munns notes that some of the people in these roles may be shared across the organisation.
For the teams this means a lot of freedom but they are empowered and held to high standards through:
- Thorough training.
- Patterns & practices defined at scale from 20+ years of experience.
- Regular metric reviews both from a business and a technical perspective.
- Sharing of new tools, services and technologies by internal experts.
Looking at what is important for Amazon working with small teams and microservices Munns’ advice to other organisations heading the same way includes:
- Culture; emphasizing that ownership and accountability go hand in hand, and that larger teams typically move slower that smaller teams. Insist on standards of excellence but not how it’s done.
- Practices; noting the importance of continuous integration (CI) and delivery (CD) as well as simplifying operational tasks.
- Tools; for the mentioned practices, for infrastructure management, for metrics and monitoring and for communication and collaboration.
Munns lastly emphasizes the importance of establishing a pattern for services and clients, thus preventing an organization from reinventing the same basic parts for things like communication, authorization, abuse prevention and service discovery. He also notes how important metrics of builds, hosts, services, etc. are to find out if the infrastructure is running as expected, if SLAs are met and so on.
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently to a service handler by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to the associated request handlers.[1]
Structure[edit]
- Resources: Any resource that can provide input to or consume output from the system.
- Synchronous Event Demultiplexer: Uses an event loop to block on all resources. When it is possible to start a synchronous operation on a resource without blocking, the demultiplexer sends the resource to the dispatcher.
- Dispatcher: Handles registering and unregistering of request handlers. Dispatches resources from the demultiplexer to the associated request handler.
Properties[edit]All reactor systems are single threaded by definition, but can exist in a multithreaded environment.
- Request Handler: An application defined request handler and its associated resource.
Benefits[edit]The reactor pattern completely separates application specific code from the reactor implementation, which means that application components can be divided into modular, reusable parts. Also, due to the synchronous calling of request handlers, the reactor pattern allows for simple coarse-grain concurrency while not adding the complexity of multiple threads to the system.
Limitations[edit]The reactor pattern can be more difficult to debug[2] than a procedural pattern due to the inverted flow of control. Also, by only calling request handlers synchronously, the reactor pattern limits maximum concurrency, especially on Symmetric multiprocessinghardware. The scalability of the reactor pattern is limited not only by calling request handlers synchronously, but also by the demultiplexer. [3]
Server components, EAR files and WAR files.. may they rest in peace
If you have lived through COM, DCOM, CORBA, EJBs, OSGi, J2EE, SOAP, SOA, DCE, etc. then you know the idea of services and components is not a new thing, but they are a date expired concept for the most part. One issue with enterprise components is they assume the use of hardware servers which are large monoliths and you want to run a lot of things on the same server. That is why we have WAR files and EAR files, and all sorts of nifty components and archives. Well turns out in 2015, that makes no sense. Operating systems and servers are ephemeral, virtualized resources and can be shipped like a component. We have EC2 images AMIs, OpenStack, Vagrant and Docker. The world changed. Move on. Microservices just recognize this trend so you are not developing like you did when the hardware, cloud orchestration, multi-cores, and virtualization was not there. You did not develop code in the 90s with punch cards did you? So don’t use an EAR file or a WAR file in 2015.
Now you can run a JVM in a Docker image which is just a process pretending to be an OS running in an OS that is running in the cloud which is running inside of a virtual machine which is running in Linux server that you don’t own that you share with people who you don’t know. Got a busy season? Well then, spin up 100 more server instances for a few weeks or hours. This is why you run Java microservices as standalone processes and not running inside of a Java EE container.
The Java EE container is no longer needed because servers are not giant refrigerator boxes that you order from Sun and wait three months for (circa 2000). Don’t fight classpath, classloader hell of Java EE. Hell your whole damn OS is now an ephemeral container (Docker). Deliver an image with all the libs you need, don’t deploy to a Java EE server which has to be versioned and configured. You are only running one service in it anyway. Turns out you don’t have five war files running in the same Java EE container since oh about 2007. Let it go.
If you are deploying a WAR file to a Java EE container then you are probably not doing microservice development. If you have more than one WAR file in the container or an EAR file, then you are definitely not doing microservice development. If you are deploying your service as an AMI or docker container and your microservice has a main method, then you might be writing a microservice.
Microservices architectures opt to break software not into components but into reusable, independently release-able services which run as one or more processes. Application and other services communicate with each other. So where we might have used a server side component, we use a microservice running in independent processes. Where we might have had WAR files or EAR files now we have a Docker container or a Amazon AMI that has the entire app preloaded and configure with exactly the libraries it needs (Java and otherwise).
JSON, HTTP, WebSocket … NO WSDL!
Now you just have to document the Microservices HTTP/JSON interface so other developers can call into it. We could say REST, and certainly you can use concepts from REST, but hey HTTP calls are enough to be considered a Microservice.
Keep this in mind: No XML. No SOAP. No WSDL. No WADL. JSON! Ok you can add some meta data and document how to talk to your service, but the idea is the docs should be documented with curl. If you are only using SOAP or XML then you are not producing a microservice. JSON is a must.
Documents should sound more like: I give you this request with these headers, params and JSON body and you respond with this JSON. Keep it simple. You can provide things in addition to JSON, but JSON is the minimum requirement. If you are not delivering up JSON and consuming JSON over HTTP or HTTP WebSocket then what you wrote is not probably not a microservice.
Call speed, non-blocking calls
One of the issues with remote calls is speed. This is why you will want to organize services around a domain that will help keep the data for that service with that service and it will not need to interact with other services or a foreign database every time it gets a request for its data. While remote calls are expensive this can be accommodated for by using async calls, batching, and WebSocket/JSON (Reactive Programming Microservice Java Lib) . Remember WebSocket allows bi-directional communication. For speed, you should prefer RPC calls that are non-blocking and can be sent in batches (POST or WebSocket). If you are able to handle requests in streams in an async manner and utilize the hardware efficiently, then you might be doing microservices development.
Another approach for increasing remote call speed is to go all SOA on your API and focus on coarser-grained responses, but this is almost always a mistake. You can write coarser-grained HTTP APIs so more is delivered with each call. This is a problem because it is harder to write and use coarser-grained HTTP APIs as they often conflate many subdomain data in the same call in the name of speed and aggregation. It is easier to batch many smaller calls and create service aggregators. You will need to do both batching and aggregation of domains (coarser grained). Dumb fast pipes and batching calls (turning them into streams) are a good indication that what you wrote is a microservice. Some call this style reactive programming.
Depending on scalability needs services may need be sharded. While a service runs in a single process for scalability that service may really be running in many processes on many virtual machine. Microservices are not stateless. Microservices should own their data. This may mean a private database. This may mean using a data lease model for elasticity. Or a private database shard per sharded service. We will talk more about this later. To learn more about how to scale microservices check out high-speed microservices. To learn more about what a Java microservice looks like read rise of the machine.
If your service is getting all of its data from a database that is shared by one or more web applications, and/or other services and/or other application, then you did not write a microservice. If you service is 100% stateless, then what you wrote is not a microservice.
Microservices do not negate the need for having libraries. If you are making many calls to a microservice, there is an indication that you maybe needed a library instead of a microservice. Adopting microservice architecture does not make you a better systems engineer. You will need some common sense, systems knowledge and/or a very good perf testing regiment. Many will fail and go back to a traditional three tier, web development version of services or some form of enterprise SOA or write a more traditional stateless web service.
Microservice, Process, DevOps
This is a point in the discussion where people conflate a lot of ideas from other pet projects or pet processes and shove that into the microservice realm. Let’s not. Something that has so many definitions tends to get diluted and meaningless.
Concepts like DevOps, continuous delivery, continuous integration, cloud computing, agile processes etc. are compelling in their own right. You don’t need to have an Agile, DevOps, Cloud setup to start getting benefits from microservice development. Certainly they complement each other. Don’t combine them as one concept. Microservices has a lot more to do with cloud, virtualization, OS containerization, etc. then it does agile development vs. RUP.
The idea of cradle-to-grave development of an application or service is not an idea that was invented in the early or late 2000s. Hiring software developers that were also systems engineers and responsible for software development, load testing, testing, and deployment is not a new concept to me at all. This is a recurring concept that I have seen in my 25 year career over and over. It is the more rare concept and one that I find completely dysfunctional where the developers tossed something over the wall to QA and ops to deploy. I feel the strong urge to tell you a lot of antidotes for my career so I have pinched myself very hard, snapped my red suspenders and yanked the hair of my white beard to resist.
Smart endpoints and dumb pipes: Actors, Reactive and Active Object
Enterprise Service Bus (ESB), and vendor driven SOA is a bad idea. It is one you hear a lot of talk about but you never see actual successful deployments of. Complex message routing, choreography, transformation, and applying business rules willy nilly and providing a graphical representation of your overly complicated runtime software process is a horrible idea. I am not saying it is never needed. You can, do and will need to integrate with legacy applications and tools like Camel et al can help, but you should not start designing your system from scratch around ESBs and Camel. It is a necessary evil at times. But evil none the less.
Yes wrapping legacy “monolithic” or yesteryears CORBA, DCOM, TPS, expensive message bus, from high-priced vendor in SOA and ESB or even good old “REST” is sometimes needed, but that does not mean that you get to redefine microservices into it. Microservices is not legacy integration. Microservices is how you develop greenfield services in 2015. It is not a legacy turd polish like SOA and ESB. (Even if sometimes you do need legacy turd polish.)
You know where a good place to store your business logic, code. Business people almost never, never, never change business rules on the fly because if they did that would be like editing code and would require testing or production would go down. This is not to say that there are not real use cases for things like Drools. This is to say Drools and Activiti are the exception not the rule. You know who is good at changing business rules in code and making sure production does not go down, your software development team. All developers prefer smart endpoints and dumb pipes because BPEL, Activiti, WS-Choreography or BPEL or orchestration are demoware bullshit. If you have ever had the joy of maintaining or trying to grok a big mass of spaghetti crapfest, you realize that creating cool, neat-o tools around legacy integration batch jobs does not make them easier to comprehend or maintain.
JSON, HTTP, WebSocket work everywhere. They work in browsers. They work from Python, Ruby, Perl processes. They work from Java. They work from PHP web applications. They work in all mobile clients. They are the least common denominator and they are simple to read and understand and document.
Web Services are great. Vendor driven SOA orchestration and ESBs are a nightmare to debug. Not all Web Services should be microservices. But you should have a very strong and powerful reason for using SOAP/WSDL/Vendor SOA.
Developers the world over prefer to use protocols that the world wide web and Unix are built on. Because it is simple to grok. Operationally predictable. Easy to cache even with third parties like Akamai and tools like Varnish. I prefer Unix cron jobs, web monitoring, cloud, etc. to ESB. Sometimes a batch job is just a batch job. Wrapping it in ESB or making a Map/Reduce cluster might make you feel more important, but is it providing business values. Sometimes it is. More often than not, it is misapplied tech. Not every batch job needs to be a Hadoop Map/Reduce or ESB orchestration, sometimes they can just be batch jobs that are kicked off by cron. (ESBs and Hadoop are needed. I am not anti-ESB or Map/Reduce).
You invoke micro services through HTTP and WebSocket or some form of messaging. You should prefer HTTP and WebSocket and only use messaging (with MOM) if you want durability. WebSocket is lightweight messaging. It is supported by all programming languages, mobile platforms and the web and it exists today. 0MQ, RabbitMQ, JMS, Kafka are all great if you need some level of durability or speed. If you do not, then WebSocket should be enough for 99% of your needs and has some added benefit of being reachable from web clients.
The message bus delivers an opaque message, so you will need to encode the message in a universally understood format, which usually ends up being JSON. There are times when you may need something faster and binary JSON-like formats abound (binary should be the exception, JSON is as fast as most binary formats, and faster than many). If something is available via a message bus call, then it should also be available via an HTTP/JSON call (REST). If you can’t exercise your service API via curl and have it return JSON, then you did not write a microservice.
With tools like Akka, QBit, Vertx, etc. the concept of an event bus or a message bus or streaming messages or streaming calls exists as core concepts to the async invocation model. Messages can be handled at first in-process by a service, as more scale is needed, those messages can be batch/forwarded to other nodes. You can write services internal to your application which are somewhere between a library and a microservice which can one day be more readily broken out into actual microservices. Reactive, Actor and Active Objects embrace the concepts of streams, message queues and event busses. They are a natural fit for a microservice architecture.
Batching of messages, back pressure based batching, are used to send courser grained messages over the wire which can minimize the performance loss of moving services to processes running on other machines. Since Akka, Finagle, QBit and Vertx support in-proc services and out of proc services using the same underlying interface to a dumb pipe, it is easier to move services in-proc or out of proc (microservice) as performance needs dictate.
If you are making a lot of blocking calls, then what you wrote is not a microservice.
Tool-stacks, polyglot programming languages
Standards are great that is why there are so many of them. Attempts to standardize on technology platforms are often thwarted by using vendor products, merging with other companies, buying companies, adopting new mobile platforms, constant churn of new client frameworks and platforms, etc. Microservices Architecture embraces polyglot programming languages and programming languages. This is where microserver HTTP/WebSocket and JSON/tolerant readers come into play as it provides a minimal pipe and format to support change and polyglot of programming languages.
Services own their data
Databases are used for reporting and offline analysis. Service stores (which could use a database), is for a service or a service shard. Operational data and reporting / historical / backup data should be split up. Operation data for a service should only be editable by that service.
Microservices architecture is back to OOP basics. Objects, services when you expose them remotely, own their data and business logic. Each service stores data and models data in its view of the world. Data is specific for its service. This is not a new concept. This is basic OOP.
In additional evidence of going back to OOP roots and domain driven development, microservices own their data storage. This could mean a database or key/value store on the same docker node as the JVM running the service (which gets replicated and backed up of course). Microservices do not use a shared database for operational data. A micro-service might fallback to a shared database if data is not in the service, but this would be the exception not the rule.
If someone thinks that Microservices are stateless it is ok to roll your eyes at them. A Microservices service edits data, and it may replicate it, shard it, and use eventual consistency to back that data up, but it owns the data and it and it alone can edit its data. If that is not what you wrote, then you did not write a microservices. In-memory computing, eventual consistency, replication, fit nicely with microservices. Remember RAM is the new disk, and the hard drive or SSD is the new tape backup. True speed is when you can edit your data without first checking to see if you have the latest copy from the database that sits on another server.
Service Discovery - Design for Failure
In addition to automated deployment, virtualization, and cloud orchestration/automation, microservices use microservices service discovery and microservices monitoring to recover from failure and to spread load across more nodes. The ability to discover service nodes, and adding them into the mix is called elasticity. This includes monitoring of services. Detecting failures. Removing unhealthy nodes out of the mix. Adding additional services into a running system.
A key component of microservices architecture is reactive programming, which is an async programming mode, and the ability to use back pressure to fail gracefully if the load surpasses the capacity of a node rather than having a cascading failure.
If your service under unexpected load becomes unresponsive then you did not write a microservice. If your service under load, throws error messages and tells clients it is under too much load, and you can spin up new nodes, and the nodes can discover each other (service discovery) and live another day, then you wrote a microservice. Microservices are resilient and elastic.
Summary
Keys ways to identify Microservices:
- Uses Service Discovery - it might be a microservice
- Async model, non-blocking - it might be a microservice
- Uses back pressure to detect when its overloaded to survive another day - it might be a microservice
- Uses monitoring to report health status - it might be a microservice
- Used a bounded domain and owns it data - it might be a microservice
- APIs are reachable via WebSocket, HTTP over JSON - it might be a microservice
- Uses Docker or an Amazon AMI - it might be a microservice
- Your service runs a single process or a set of sharded services - it might be a microservice
- You don’t hard code locations of services, you use service discovery like etcd, consul, or some other cloud friendly, elastic way to spin up services
- You also store other forms of config in cloud friendly places like etcd and consul (or s3 or inside the hidden ec2 instance web server), and you can get updates while the service is running
- You use back pressure. If you service gets overloaded, it does not become unresponsive, it sends currently unavailable messages so upstream clients and services can route around it (they could even get the last known good whatever from s3 or from Akamai.)
- One downstream service that in unresponsive will not kill all upstream services and clients
Keys ways to identify Java Microservices
- You don’t use an EAR or WAR files
- Your services have main methods
- You don’t auto-deploy java components, you auto-deploy AMI images or docker containers
- You use a fatjar that is runnable as a process (or sharded services)
- Or you use gradle distZip or distTar
- Your code is non-blocking. If you have to use a blocking API for integration, you do it from a non-blocking worker pool.
Just remember Microservices are not a new thing, and they are not cool or hip. Microservices are obvious evolutionary architecture to address the revolutionary things that already happened: web, cloud, mobile, server virtualization, OS containerization, multi-core servers, cheaper and cheaper RAM, 64 bit computing, 10GBE, 100GBE, etc. This is not extreme or cool. This is obvious reactionary architecture to this amazing tech landscape that we live in. It is less about the fashion show of technology coolness and more about not using tools and techniques that are antiques in this environment. Give up your punch cards, and WAR files, and join in.
I have more to say but this blog post is way too long already. I leave you with these links. Thank you for reading if you got this far.
Using Domain-Driven Design When Creating Microservices
Expecting Failures In Microservices and Working Around Them
Don’t Think like an Engineer When Designing Microservices
Using Domain-Driven Design When Creating Microservices
Expecting Failures In Microservices and Working Around Them
Don’t Think like an Engineer When Designing Microservices
No comments:
Post a Comment