The Way of the Gopher — Medium:
"And the non-blocking code? As requests are processed and events are triggered, messages are queued along with their respective callback functions. To explain further, here’s an excerpt from a particularly insightful blog post from Carbon Five: In a loop, the queue is polled for the next message (each poll referred to as a “tick”) and when a message is encountered, the callback for that message is executed. The calling of this callback function serves as the initial frame in the call stack, and due to JavaScript being single-threaded, further message polling and processing is halted pending the return of all calls on the stack. Subsequent (synchronous) function calls add new call frames to the stack... Our Node service may have handled incoming requests like champ if all it needed to do was return immediately available data. But instead it was waiting on a ton of nested callbacks all dependent on responses from S3 (which can be god awful slow at times). Consequently, when any request timeouts happened, the event and its associated callback was put on an already overloaded message queue. While the timeout event might occur at 1 second, the callback wasn’t getting processed until all other messages currently on the queue, and their corresponding callback code, were finished executing (potentially seconds later). I can only imagine the state of our stack during the request spikes."
In light of these realizations, it was time to entertain the idea that maybe Node.js wasn’t the perfect candidate for the job. My CTO and I sat down and had a chat about our options. We certainly didn’t want to continue bouncing Octo every other week and we were both very interested in a promising case study that had cropped up on the internet:
'via Blog this'
Thursday, 31 March 2016
InfoQ: Full Stack Testing: Balancing Unit and End-to-End Tests
Full Stack Testing: Balancing Unit and End-to-End Tests:
"At their core, tests make sure your application is doing what you intend it to do. They are an automated script to execute your code and check that it did what you expected. The better they are, the more you can rely on them to gate your deployments. Where your tests are weak, you either need a QA team or you ship buggy software (both mean your users get value at a much slower pace than is ideal). Where your tests are strong, you can ship confidently and quickly, without approvals or slow, manual processes like QA. You must also balance the future maintainability of the tests you write.
Your application will change and thus so will your tests. Ideally, your tests only have to change proportionally to the change you are making in your software. If you are making a change in an error message, you don’t want to have to rewrite a lot of your test suite. But, if you are completely changing a user flow, it reasonable to expect to rewrite a lot of tests.
Practically speaking, this means you can’t do all your testing as end-to-end full-blown integration tests, but you also can’t do it as nothing but tiny little unit tests. This is about how to strike that balance."
'via Blog this'
"At their core, tests make sure your application is doing what you intend it to do. They are an automated script to execute your code and check that it did what you expected. The better they are, the more you can rely on them to gate your deployments. Where your tests are weak, you either need a QA team or you ship buggy software (both mean your users get value at a much slower pace than is ideal). Where your tests are strong, you can ship confidently and quickly, without approvals or slow, manual processes like QA. You must also balance the future maintainability of the tests you write.
Your application will change and thus so will your tests. Ideally, your tests only have to change proportionally to the change you are making in your software. If you are making a change in an error message, you don’t want to have to rewrite a lot of your test suite. But, if you are completely changing a user flow, it reasonable to expect to rewrite a lot of tests.
Practically speaking, this means you can’t do all your testing as end-to-end full-blown integration tests, but you also can’t do it as nothing but tiny little unit tests. This is about how to strike that balance."
'via Blog this'
Linux IOVisor versus Data Plane Development Kit
Data Plane Development Kit - Wikipedia, the free encyclopedia: "The Data Plane Development Kit (DPDK) is a set of data plane libraries and network interface controller drivers for fast packet processing. The DPDK provides a programming framework for Intel x86 processors and enables faster development of high speed data packet networking applications.[1][2] It scales from Intel Atom processors to Intel Xeon processors and support for other processor architectures like IBM POWER8 are under progress.[3] It is provided and supported under the open source[4] BSD license."
http://www.linuxfoundation.org/news-media/announcements/2015/08/test
“IO Visor will work closely with the Linux kernel community to advance universal IO extensibility for Linux. This collaboration is critically important as virtualization is putting more demands on flexibility, performance and security,” said Jim Zemlin, executive director, The Linux Foundation. “Open source software and collaborative development are the ingredients for addressing massive change in any industry. IO Visor will provide the essential framework for this work on Linux virtualization and networking.”
"Advancing IO and network virtualization in the Linux stack can be an enabler of agility and elasticity, which are key requirements for cloud deployments and applications. IO Visor Project’s mission to bring universal IO extensibility to the Linux kernel will accelerate innovation of virtual network functions in SDN and NFV deployments,” said Rohit Mehra, Vice President of Network Infrastructure, IDC. “The ability to create, load and unload in-kernel functions will enable developers in many upstream and downstream open source projects. What’s more, as an initiative under the auspices of the Linux Foundation, the IO Visor Project has the potential for credibility and momentum to benefit the diverse community of vendors and service providers, and ultimately enterprise IT.”
Two New eBPF Tools: memleak and argdist | All Your Base Are Belong To Us
Two New eBPF Tools: memleak and argdist | All Your Base Are Belong To Us: "
Warning: This post requires a bit of background. I strongly recommend Brendan Gregg’s introduction to eBPF and bcc. With that said, the post below describes two new bcc-based tools, which you can use directly without perusing the implementation details.
A few weeks ago, I started experimenting with eBPF. In a nutshell, eBPF (introduced in Linux kernel 3.19 and further improved in 4.x kernels) allows you to attach verifiably-safe programs to arbitrary functions in the kernel or a user process. These little programs, which execute in kernel mode, can collect performance information, trace diagnostic data, and aggregate statistics that are then exposed to user mode. Although BPF’s lingua franca is a custom instruction set, the bcc project provides a C-to-BPF compiler and a Python module that can be used from user mode to load BPF programs, attach them, and print their results. The bcc repository contains numerous examples of using BPF programs, and a growing collection of tracing tools that perform in-kernel aggregations, offering much lower overhead than perf or similar alternatives. The result of my work is currently two new scripts: memleak and argdist. memleak is a script that helps detect memory leaks in kernel components or user processes by keeping track of allocations that haven’t been freed including the call stack that performed the allocation. argdist is a generic tool that traces function arguments into a histogram or frequency counting table to explore a function’s behavior over time. To experiment with the tools in this post, you will need to install bcc on a modern kernel (4.1+ is recommended). Instructions and prerequisites are available on the bcc installation page."
'via Blog this'
Warning: This post requires a bit of background. I strongly recommend Brendan Gregg’s introduction to eBPF and bcc. With that said, the post below describes two new bcc-based tools, which you can use directly without perusing the implementation details.
A few weeks ago, I started experimenting with eBPF. In a nutshell, eBPF (introduced in Linux kernel 3.19 and further improved in 4.x kernels) allows you to attach verifiably-safe programs to arbitrary functions in the kernel or a user process. These little programs, which execute in kernel mode, can collect performance information, trace diagnostic data, and aggregate statistics that are then exposed to user mode. Although BPF’s lingua franca is a custom instruction set, the bcc project provides a C-to-BPF compiler and a Python module that can be used from user mode to load BPF programs, attach them, and print their results. The bcc repository contains numerous examples of using BPF programs, and a growing collection of tracing tools that perform in-kernel aggregations, offering much lower overhead than perf or similar alternatives. The result of my work is currently two new scripts: memleak and argdist. memleak is a script that helps detect memory leaks in kernel components or user processes by keeping track of allocations that haven’t been freed including the call stack that performed the allocation. argdist is a generic tool that traces function arguments into a histogram or frequency counting table to explore a function’s behavior over time. To experiment with the tools in this post, you will need to install bcc on a modern kernel (4.1+ is recommended). Instructions and prerequisites are available on the bcc installation page."
'via Blog this'
Probing the JVM with BPF/BCC | All Your Base Are Belong To Us
Probing the JVM with BPF/BCC | All Your Base Are Belong To Us: "Probing the JVM with BPF/BCC
Now that BCC has support for USDT probes, another thing I wanted to try is look at OpenJDK probes and extract some useful examples. To follow along, install a recent OpenJDK (I used 1.8) that has USDT probes enabled.
On my Fedora 22, sudo dnf install java was just enough for everything. Conveniently, OpenJDK ships with a set of .stp files that contain probe definitions. Here’s an example — and there are many more in your $JAVA_HOME/tapset directory:"
'via Blog this'
Now that BCC has support for USDT probes, another thing I wanted to try is look at OpenJDK probes and extract some useful examples. To follow along, install a recent OpenJDK (I used 1.8) that has USDT probes enabled.
On my Fedora 22, sudo dnf install java was just enough for everything. Conveniently, OpenJDK ships with a set of .stp files that contain probe definitions. Here’s an example — and there are many more in your $JAVA_HOME/tapset directory:"
'via Blog this'
Wednesday, 30 March 2016
To SQL or NoSQL? That’s the database question | Ars Technica
To SQL or NoSQL? That’s the database question | Ars Technica: "It's increasingly apparent that for many, it's no longer an issue of SQL vs. NoSQL. Instead, it's SQL and NoSQL, with both having their own clear places—and increasingly being integrated into each other. Microsoft, Oracle, and Teradata, for example, are now all selling some form of Hadoop integration to connect SQL-based analysis to the world of unstructured big data. ]As Teradata General Manager of Enterprise Systems Dan Graham tells it, the move to embrace Hadoop was pushed largely by one big customer. Netflix was beating Teradata over the head until the company broke down and dragged everything into the cloud—Amazon Cloud, where most of your movies are now sitting, along with a bunch of other data. The result was a hybrid environment of Amazon Hadoop plus Teradata Cloud for Hadoop, which aims to take care of the heavy lifting with Hadoop monitoring, maintenance, and installation. Teradata is now actually selling Hadoop itself and using its own SQL query optimizer technology to serve it up to business customers' tools. "If you know what you're doing, [Hadoop is] really not competing with us," Graham said. "It's the difference between a big Ford truck and a BMW sedan. Do they compete? A little, yes. But if you do best-pick engineering, you'll get what you need. If you're carrying refrigerators, or bags of cement, you don't want to put them in a BMW. You put it in a Ford 150.""
'via Blog this'
'via Blog this'
Monday, 28 March 2016
You can be a kernel hacker! - Julia Evans
You can be a kernel hacker! - Julia Evans: "
When I started Hacker School, I wanted to learn how the Linux kernel works. I'd been using Linux for ten years, but I still didn't understand very well what my kernel did. While there, I found out that: the Linux kernel source code isn't all totally impossible to understand kernel programming is not just for wizards, it can also be for me! systems programming is REALLY INTERESTING I could write toy kernel modules, for fun! and, most surprisingly of all, all of this stuff was useful. I hadn't been doing low level programming at all -- I'd written a little bit of C in university, and otherwise had been doing web development and machine learning. But it turned out that my newfound operating systems knowledge helped me solve regular programming tasks more easily. I also now feel like if I were to be put on Survivor: fix a bug in my kernel's USB driver, I'd stand a chance of not being immediately kicked off the island. This is all going to be about Linux, but a lot of the same concepts apply to OS X. We'll talk about
When I started Hacker School, I wanted to learn how the Linux kernel works. I'd been using Linux for ten years, but I still didn't understand very well what my kernel did. While there, I found out that: the Linux kernel source code isn't all totally impossible to understand kernel programming is not just for wizards, it can also be for me! systems programming is REALLY INTERESTING I could write toy kernel modules, for fun! and, most surprisingly of all, all of this stuff was useful. I hadn't been doing low level programming at all -- I'd written a little bit of C in university, and otherwise had been doing web development and machine learning. But it turned out that my newfound operating systems knowledge helped me solve regular programming tasks more easily. I also now feel like if I were to be put on Survivor: fix a bug in my kernel's USB driver, I'd stand a chance of not being immediately kicked off the island. This is all going to be about Linux, but a lot of the same concepts apply to OS X. We'll talk about
- what even is a kernel?
- why bother learning about this stuff?
- A few strategies for understanding the Linux kernel better, on your own terms:
- strace all the things!
- Read some kernel code!
- Write a fun kernel module!
- Write an operating system!
- Try the Eudyptula challenge"
Brendan D. Gregg: Linux perf Examples
Linux perf Examples:
"These are some examples of using the perf Linux profiler, which has also been called Performance Counters for Linux (PCL), Linux perf events (LPE), or perf_events. Like Vince Weaver, I'll call it perf_events so that you can search on that term later. Searching for just "perf" finds sites on the police, petroleum, weed control, and a T-shirt. This is not an official perf page, for either perf_events or the T-shirt."
Julia Evans: How does perf work? (in which we read the Linux kernel source)
"These are some examples of using the perf Linux profiler, which has also been called Performance Counters for Linux (PCL), Linux perf events (LPE), or perf_events. Like Vince Weaver, I'll call it perf_events so that you can search on that term later. Searching for just "perf" finds sites on the police, petroleum, weed control, and a T-shirt. This is not an official perf page, for either perf_events or the T-shirt."
Julia Evans: How does perf work? (in which we read the Linux kernel source)
What happens if you write a TCP stack in Python? - Julia Evans
What happens if you write a TCP stack in Python? - Julia Evans:
"During Hacker School, I wanted to understand networking better, and I decided to write a miniature TCP stack as part of that. I was much more comfortable with Python than C and I'd recently discovered the scapy networking library which made sending packets really easy. So I started writing teeceepee!
The basic idea was:
I didn't care much about proper error handling or anything; I just wanted to get one webpage and declare victory :)"
Traceroute in 15 lines of code using Scapy
'via Blog this'
"During Hacker School, I wanted to understand networking better, and I decided to write a miniature TCP stack as part of that. I was much more comfortable with Python than C and I'd recently discovered the scapy networking library which made sending packets really easy. So I started writing teeceepee!
The basic idea was:
- open a raw network socket that lets me send TCP packets
- send a HTTP request to GET google.com
- get and parse a response
- celebrate!
I didn't care much about proper error handling or anything; I just wanted to get one webpage and declare victory :)"
Traceroute in 15 lines of code using Scapy
'via Blog this'
Why you should understand (a little) about TCP - Julia Evans
Why you should understand (a little) about TCP - Julia Evans:
"Delayed ACKs & TCP_NODELAY
Ruby's Net::HTTP splits POST requests across two TCP packets - one for the headers, and another for the body. curl, by contrast, combines the two if they'll fit in a single packet. To make things worse, Net::HTTP doesn't set TCP_NODELAY on the TCP socket it opens, so it waits for acknowledgement of the first packet before sending the second. This behaviour is a consequence of Nagle's algorithm. Moving to the other end of the connection, HAProxy has to choose how to acknowledge those two packets. In version 1.4.18 (the one we were using), it opted to use TCP delayed acknowledgement. Delayed acknowledgement interacts badly with Nagle's algorithm, and causes the request to pause until the server reaches its delayed acknowledgement timeout.."
'via Blog this'
"Delayed ACKs & TCP_NODELAY
Ruby's Net::HTTP splits POST requests across two TCP packets - one for the headers, and another for the body. curl, by contrast, combines the two if they'll fit in a single packet. To make things worse, Net::HTTP doesn't set TCP_NODELAY on the TCP socket it opens, so it waits for acknowledgement of the first packet before sending the second. This behaviour is a consequence of Nagle's algorithm. Moving to the other end of the connection, HAProxy has to choose how to acknowledge those two packets. In version 1.4.18 (the one we were using), it opted to use TCP delayed acknowledgement. Delayed acknowledgement interacts badly with Nagle's algorithm, and causes the request to pause until the server reaches its delayed acknowledgement timeout.."
'via Blog this'
Fun with stats: How big of a sample size do I need? - Julia Evans
Fun with stats: How big of a sample size do I need? - Julia Evans:
"So what we've learned already, without even doing any statistics, is that if you're doing an experiment with two possible outcomes, and you're doing 10 trials, that's terrible. If you do 10,000 trials, that's pretty good, and if you see a big difference, like 80% / 20%, you can almost certainly rely on it. But if you're trying to detect a small difference like 50.3% / 49.7%, that's not a big enough difference to detect with only 10,000 trials.
So far this has all been totally handwavy. There are a couple of ways to formalize our claims about sample size. One really common way is by doing hypothesis testing. So let's do that!
Let's imagine that our experiment is that we're asking people whether they like mustard or not. We need to make a decision now about our experiment.
Step 1: make a null hypothesis
Let's say that we've talked to 10 people, and 7/10 of them like mustard. We are not fooled by small sample sizes and we ALREADY KNOW that we can't trust this information. But your brother is arguing "7/10 seems like a lot! I like mustard! I totally believe this!". You need to argue with him with MATH. So we're going to make what's called a "null hypothesis", and try to disprove it. In this case, let's make the null hypothesis "there's a 50/50 chance that a given person likes mustard"."'via Blog this'
"So what we've learned already, without even doing any statistics, is that if you're doing an experiment with two possible outcomes, and you're doing 10 trials, that's terrible. If you do 10,000 trials, that's pretty good, and if you see a big difference, like 80% / 20%, you can almost certainly rely on it. But if you're trying to detect a small difference like 50.3% / 49.7%, that's not a big enough difference to detect with only 10,000 trials.
So far this has all been totally handwavy. There are a couple of ways to formalize our claims about sample size. One really common way is by doing hypothesis testing. So let's do that!
Let's imagine that our experiment is that we're asking people whether they like mustard or not. We need to make a decision now about our experiment.
Step 1: make a null hypothesis
Let's say that we've talked to 10 people, and 7/10 of them like mustard. We are not fooled by small sample sizes and we ALREADY KNOW that we can't trust this information. But your brother is arguing "7/10 seems like a lot! I like mustard! I totally believe this!". You need to argue with him with MATH. So we're going to make what's called a "null hypothesis", and try to disprove it. In this case, let's make the null hypothesis "there's a 50/50 chance that a given person likes mustard"."'via Blog this'
High Performance Browser Networking
High Performance Browser Networking:
Our goal is to cover what every developer should know about the network: what protocols are being used and their inherent limitations, how to best optimize your applications for the underlying network, and what networking capabilities the browser offers and when to use them.
In the process, we will look at the internals of TCP, UDP, and TLS protocols, and how to optimize our applications and infrastructure for each one. Then we’ll take a deep dive into how the wireless and mobile networks work under the hood—this radio thing, it’s very different—and discuss its implications for how we design and architect our applications. Finally, we will dissect how the HTTP protocol works under the hood and investigate the many new and exciting networking capabilities in the browser:
- Upcoming HTTP/2 improvements
- New XHR features and capabilities
- Data streaming with Server-Sent Events
- Bidirectional communication with WebSocket
- Peer-to-peer video and audio communication with WebRTC
- Peer-to-peer data exchange with DataChannel
Understanding how the individual bits are delivered, and the properties of each transport and protocol in use are essential knowledge for delivering high-performance applications. After all, if our applications are blocked waiting on the network, then no amount of rendering, JavaScript, or any other form of optimization will help! Our goal is to eliminate this wait time by getting the best possible performance from the network.
High-Performance Browser Networking will be of interest to anyone interested in optimizing the delivery and performance of her applications, and more generally, curious minds that are not satisfied with a simple checklist but want to know how the browser and the underlying protocols actually work under the hood. The "how" and the "why" go hand in hand: we’ll cover practical advice about configuration and architecture, and we’ll also explore the trade-offs and the underlying reasons for each optimization.
Julia Evans: Thread pools! How do I use them?
http://jvns.ca/blog/2016/03/27/thread-pools-how-do-i-use-them/
In Java, a thread is "blocked" when it's waiting for a "monitor" on an object. When I originally googled this I was like "er what's a monitor?". It's when you use synchronization to make sure two different threads don't execute the same code at the same time.
This
synchronize means that only one thread is allowed to run this x += 1block at a time, so you don't accidentally end up in a race. If one thread is already doing x += 1, the other threads end up -- you guessed it -- BLOCKED.
The two things that were blocking my threads were:
lazyvals in Scala usedsynchronizedinternally, and so can cause problems with concurrencyDouble.parseDoublein Java 7 is a synchronized method. So only one thread can parse doubles from strings at a time. Really? Really. They fixed it in Java 8 though so that's good.
The Data Lifecycle, Part One: Avroizing the Enron Emails - Hortonworks
The Data Lifecycle, Part One: Avroizing the Enron Emails - Hortonworks: "
This is part one of a series of blog posts covering new developments in the Hadoop pantheon that enable productivity throughout the lifecycle of big data. In a series of posts, we’re going to explore the full lifecycle of data in the enterprise: Introducing new data sources to the Hadoop filesystem via ETL, processing this data in data-flows with Pig and Python to expose new and interesting properties, consuming this data as an analyst in HIVE, and discovering and accessing these resources as analysts and application developers using HCatalog and Templeton."
This is part one of a series of blog posts covering new developments in the Hadoop pantheon that enable productivity throughout the lifecycle of big data. In a series of posts, we’re going to explore the full lifecycle of data in the enterprise: Introducing new data sources to the Hadoop filesystem via ETL, processing this data in data-flows with Pig and Python to expose new and interesting properties, consuming this data as an analyst in HIVE, and discovering and accessing these resources as analysts and application developers using HCatalog and Templeton."
Sunday, 27 March 2016
Docker, not production-ready? Not so, says Docker | InfoWorld
Docker, not production-ready? Not so, says Docker | InfoWorld:
"Yet the question remains: When will Docker be used in production? Developers have driven Docker adoption because it streamlines development and vastly simplifies deployment. But the immature nature of security and container management solutions around Docker have kept it largely a dev-and-test affair.
That may be changing. According to a recent O’Reilly Media study, 40 percent of respondents already run Docker in production. Docker has 75-plus paying enterprise customers for its data center product, which was made generally available in February, and almost 6,000 paying customers of Docker Cloud, the company’s hosted service.
It seems safe to assume that Docker isn’t being used to containerize existing enterprise applications. Instead, developers are bringing in Docker for new application deployments, greenfield opportunities that aren’t dependent on yesterday’s infrastructure. As RedMonk analyst Fintan Ryan has said:
Where we are seeing a massive difference with the use of containers is around greenfield projects. These greenfield projects generally have as close to a blank slate as you are going to find in the enterprise, and with them containers are going into production incredibly quickly -- much faster than before.
Indeed, former Appfog CEO Lucas Carlson believes Docker containers are suitable for such cloud-native applications only: “[T]he benefits of containers can only be achieved when the applications run within containers have been built-for-cloud.”
Not everyone agrees with that assessment. On the contrary, Docker CEO Ben Golub told me, “there is ample evidence to show that Docker is being embraced by early majority/pragmatist organizations,” among them Fortune 100 pharmaceutical, retail, health care, manufacturing, and media companies. Some specific customer examples:
ADP is moving its core application to a solution based on Docker Data Center and Docker Swarm
Goldman Sachs is moving 90 percent of its applications to Docker over the course of the next 12 months
The General Services Administration is basing its entire next-generation platform (which tracks $1.7 trillion) on Docker
Multiple U.S. Department of Defense agencies are running truly "mission-critical" apps on Docker"
"Yet the question remains: When will Docker be used in production? Developers have driven Docker adoption because it streamlines development and vastly simplifies deployment. But the immature nature of security and container management solutions around Docker have kept it largely a dev-and-test affair.
That may be changing. According to a recent O’Reilly Media study, 40 percent of respondents already run Docker in production. Docker has 75-plus paying enterprise customers for its data center product, which was made generally available in February, and almost 6,000 paying customers of Docker Cloud, the company’s hosted service.
It seems safe to assume that Docker isn’t being used to containerize existing enterprise applications. Instead, developers are bringing in Docker for new application deployments, greenfield opportunities that aren’t dependent on yesterday’s infrastructure. As RedMonk analyst Fintan Ryan has said:
Where we are seeing a massive difference with the use of containers is around greenfield projects. These greenfield projects generally have as close to a blank slate as you are going to find in the enterprise, and with them containers are going into production incredibly quickly -- much faster than before.
Indeed, former Appfog CEO Lucas Carlson believes Docker containers are suitable for such cloud-native applications only: “[T]he benefits of containers can only be achieved when the applications run within containers have been built-for-cloud.”
Not everyone agrees with that assessment. On the contrary, Docker CEO Ben Golub told me, “there is ample evidence to show that Docker is being embraced by early majority/pragmatist organizations,” among them Fortune 100 pharmaceutical, retail, health care, manufacturing, and media companies. Some specific customer examples:
ADP is moving its core application to a solution based on Docker Data Center and Docker Swarm
Goldman Sachs is moving 90 percent of its applications to Docker over the course of the next 12 months
The General Services Administration is basing its entire next-generation platform (which tracks $1.7 trillion) on Docker
Multiple U.S. Department of Defense agencies are running truly "mission-critical" apps on Docker"
GitHub - 0xAX/linux-insides: A little bit about a linux kernel
GitHub - 0xAX/linux-insides: A little bit about a linux kernel:
linux-insides
A series of posts about the linux kernel and its insides.
The goal is simple - to share my modest knowledge about the insides of the linux kernel and help people who are interested in linux kernel insides, and other low-level subject matter.
linux-insides
A series of posts about the linux kernel and its insides.
The goal is simple - to share my modest knowledge about the insides of the linux kernel and help people who are interested in linux kernel insides, and other low-level subject matter.
Thursday, 24 March 2016
3 Things We Learnt from ‘Reactive Microservices Architecture’ | Voxxed
3 Things We Learnt from ‘Reactive Microservices Architecture’ | Voxxed:
The march towards Microservices isn’t just about technology
Bonér observes that the ideas encapsulated by the buzzy term Microservices actually predate the trend by quite some distance, and even outpace microservice fore-runner Service Oriented Architecture (SOA). In the past, however, Bonér writes, “Certain technical constraints held us back from taking the concepts embedded within the Microervices term to the next level: single machines running single core processors, slow networks, expensive disks, expensive RAM, and organizations structured as monoliths. Ideas such as organizing systems into well-defined components with a single responsibility are not new.” In 2016, with the advent of cheap RAM and multi-core processors, zippier networks and the dawn of the Cloud, systems can now be structured “with the customer in mind. As a result, “Microservices are more than a series of principles and technologies. They’re a way to approach the complex problem of systems design in a more empathetic way.”
Isolation is king in Microservices
For Bonér, isolation represents “the foundation for many of the high-level benefits in Microservices.” But, as Conway’s Law predicted in 1967, it’s also the trait that will most heavily influence your design and architecture, and will even influence how you divvy up your teams and responsibilities, given that any system you design will most like produce a design which structure mimics that of an organisation’s communication structure. With this in mind, you need to ensure that any failure can be contained and isolated “without having it cascade throughout the services participating in the workflow.” Isolation also prompts the natural rollout of Continuous Delivery for incremental changes on a service by service basis, and allows for easier scalability and monitoring.
REST in Microservices is definitely not Lightbend’s jam
Although for some REST has come to be considered as the de facto communication protocol by many for Microservices, this is not something Bonér would advocate. In fact, because REST tends to be synchronous, he sees it a “very unfitting default protocol for inter-service communication.” If you must use REST, try to limit it to a handful of services, or “situations between specific tightly coupled services.” And, Bonér adds starkly, “use it sparingly, outside the regular request/response cycle, knowing that it is always at the expense of decoupling, system evolution, scale and availability.”
The march towards Microservices isn’t just about technology
Bonér observes that the ideas encapsulated by the buzzy term Microservices actually predate the trend by quite some distance, and even outpace microservice fore-runner Service Oriented Architecture (SOA). In the past, however, Bonér writes, “Certain technical constraints held us back from taking the concepts embedded within the Microervices term to the next level: single machines running single core processors, slow networks, expensive disks, expensive RAM, and organizations structured as monoliths. Ideas such as organizing systems into well-defined components with a single responsibility are not new.” In 2016, with the advent of cheap RAM and multi-core processors, zippier networks and the dawn of the Cloud, systems can now be structured “with the customer in mind. As a result, “Microservices are more than a series of principles and technologies. They’re a way to approach the complex problem of systems design in a more empathetic way.”
Isolation is king in Microservices
For Bonér, isolation represents “the foundation for many of the high-level benefits in Microservices.” But, as Conway’s Law predicted in 1967, it’s also the trait that will most heavily influence your design and architecture, and will even influence how you divvy up your teams and responsibilities, given that any system you design will most like produce a design which structure mimics that of an organisation’s communication structure. With this in mind, you need to ensure that any failure can be contained and isolated “without having it cascade throughout the services participating in the workflow.” Isolation also prompts the natural rollout of Continuous Delivery for incremental changes on a service by service basis, and allows for easier scalability and monitoring.
REST in Microservices is definitely not Lightbend’s jam
Although for some REST has come to be considered as the de facto communication protocol by many for Microservices, this is not something Bonér would advocate. In fact, because REST tends to be synchronous, he sees it a “very unfitting default protocol for inter-service communication.” If you must use REST, try to limit it to a handful of services, or “situations between specific tightly coupled services.” And, Bonér adds starkly, “use it sparingly, outside the regular request/response cycle, knowing that it is always at the expense of decoupling, system evolution, scale and availability.”
braydie/HowToBeAProgrammer: A guide on how to be a Programmer - originally published by Robert L Read
braydie/HowToBeAProgrammer: A guide on how to be a Programmer - originally published by Robert L Read:
To be a good programmer is difficult and noble. The hardest part of making real a collective vision of a software project is dealing with one's coworkers and customers. Writing computer programs is important and takes great intelligence and skill. But it is really child's play compared to everything else that a good programmer must do to make a software system that succeeds for both the customer and myriad colleagues for whom she is partially responsible. In this essay I attempt to summarize as concisely as possible those things that I wish someone had explained to me when I was twenty-one.
This is very subjective and, therefore, this essay is doomed to be personal and somewhat opinionated. I confine myself to problems that a programmer is very likely to have to face in her work. Many of these problems and their solutions are so general to the human condition that I will probably seem preachy. I hope in spite of this that this essay will be useful.
To be a good programmer is difficult and noble. The hardest part of making real a collective vision of a software project is dealing with one's coworkers and customers. Writing computer programs is important and takes great intelligence and skill. But it is really child's play compared to everything else that a good programmer must do to make a software system that succeeds for both the customer and myriad colleagues for whom she is partially responsible. In this essay I attempt to summarize as concisely as possible those things that I wish someone had explained to me when I was twenty-one.
This is very subjective and, therefore, this essay is doomed to be personal and somewhat opinionated. I confine myself to problems that a programmer is very likely to have to face in her work. Many of these problems and their solutions are so general to the human condition that I will probably seem preachy. I hope in spite of this that this essay will be useful.
Wednesday, 23 March 2016
Functional from the Roots Up: Why Java Devs Should Look at Scala | Voxxed
Functional from the Roots Up: Why Java Devs Should Look at Scala | Voxxed:
So aside from ignoring that joke, say a Java developer says, “I’m kind of interested in Scala, I’m going to check some stuff out”…have you got any advice for them to leave at the door?
One piece of advice I gave in the session is that there are a lot of syntactic constructs in Scala that look like Java, but they’re not.
The one that I really focused on, which Twitter picked up, was the notion of the for loop in Scala. It’s not really a for loop – it’s a for comprehension, is the term they use, and it’s actually a different creature entirely from what we’re used to in Java. The other thing that I think a lot of people coming from Java, coming into Scala, will find very powerful is pattern matching. It kind of on the surface looks like a switch case, but that’s kind of like saying a kitten looks like a T-Rex.
There’s a huge order of magnitude more power in pattern matching, to the point where, if you took away every other control construct from me, and just left me with pattern matching, I’d be OK. Because, it can do fls, it can do all this other decision making, etc, etc. It’s an extraordinarily powerful construct.
The last thing you probably need to do is let go of some of the obsessive desire that Java developers have around the physical construction of their code…You shouldn’t really have to worry about some of the physical details, as long as it all works. And so, a Java developer is going to have to, to quote Yoda – which is always a good one to quote – “Unlearn you must.”
So aside from ignoring that joke, say a Java developer says, “I’m kind of interested in Scala, I’m going to check some stuff out”…have you got any advice for them to leave at the door?
One piece of advice I gave in the session is that there are a lot of syntactic constructs in Scala that look like Java, but they’re not.
The one that I really focused on, which Twitter picked up, was the notion of the for loop in Scala. It’s not really a for loop – it’s a for comprehension, is the term they use, and it’s actually a different creature entirely from what we’re used to in Java. The other thing that I think a lot of people coming from Java, coming into Scala, will find very powerful is pattern matching. It kind of on the surface looks like a switch case, but that’s kind of like saying a kitten looks like a T-Rex.
There’s a huge order of magnitude more power in pattern matching, to the point where, if you took away every other control construct from me, and just left me with pattern matching, I’d be OK. Because, it can do fls, it can do all this other decision making, etc, etc. It’s an extraordinarily powerful construct.
The last thing you probably need to do is let go of some of the obsessive desire that Java developers have around the physical construction of their code…You shouldn’t really have to worry about some of the physical details, as long as it all works. And so, a Java developer is going to have to, to quote Yoda – which is always a good one to quote – “Unlearn you must.”
Tuesday, 22 March 2016
5 years of Scala and counting – debunking some myths about the language and its environment | manuel.bernhardt.io
5 years of Scala and counting – debunking some myths about the language and its environment | manuel.bernhardt.io:
There are many rants about Scala out there. This isn’t one of them. I’m not here to complain, but rather to applaud.
This post is intended for developers curious about Scala or have heard about it some time ago but never quite got to look more into it, put off by a feeling of “well this is a show-stopper for me”. If you’re a Scala aficionado you are of course welcome to read it and share it.
It consists of 3 parts:
– my favourite “killer features”
– debunking some of the Scala myths that still float around in the JVM community
– some advice for learning Scala
There are many rants about Scala out there. This isn’t one of them. I’m not here to complain, but rather to applaud.
This post is intended for developers curious about Scala or have heard about it some time ago but never quite got to look more into it, put off by a feeling of “well this is a show-stopper for me”. If you’re a Scala aficionado you are of course welcome to read it and share it.
It consists of 3 parts:
– my favourite “killer features”
– debunking some of the Scala myths that still float around in the JVM community
– some advice for learning Scala
comparethecloud: What exactly is hybrid cloud: A stepping stone, a sanctuary for regulated industries or a rampart for old tech vendors? -
What exactly is hybrid cloud: A stepping stone, a sanctuary for regulated industries or a rampart for old tech vendors? -:
So what’s stopping everyone moving to public cloud?
One old expression still holds true: “Why do people rob banks? Because that’s where the money is!”
The fact that the banks remain the main target for hackers and cybercriminals of all kinds means that a heightened level of security is essential. Some time ago banks were described as simply technology companies with a banking licence, because everything they did was already digitised. It might be more accurate to describe them as security companies, because everything they do is based on trust, if their security is compromised and trust is lost, a bank is out of business.
This is not to argue that private environments always have lower latency and higher security then public ones, but whatever level of regulatory certification AWS, Azure and Google obtain, the banks are going to want to be hyper secure.
So what’s stopping everyone moving to public cloud?
One old expression still holds true: “Why do people rob banks? Because that’s where the money is!”
The fact that the banks remain the main target for hackers and cybercriminals of all kinds means that a heightened level of security is essential. Some time ago banks were described as simply technology companies with a banking licence, because everything they did was already digitised. It might be more accurate to describe them as security companies, because everything they do is based on trust, if their security is compromised and trust is lost, a bank is out of business.
This is not to argue that private environments always have lower latency and higher security then public ones, but whatever level of regulatory certification AWS, Azure and Google obtain, the banks are going to want to be hyper secure.
Whatever level of regulatory certification vendors obtain, the banks are going to want to be hyper secure.
After all, while AWS beat all the competition (IBM included) to win the CIA’s business, the CIA doesn’t use the main AWS cloud facilities. Instead it uses an especially secure private cloud provided by Amazon. Should the banks settle for anything less?
Saturday, 19 March 2016
Efficiency Over Speed: Getting More Performance Out of Kafka Consumer - SignalFx
Efficiency Over Speed: Getting More Performance Out of Kafka Consumer - SignalFx:
At the last Kafka meetup at LinkedIn in Mountain View, I presented some work we’ve done at SignalFx to get significant performance gains by writing our own consumer/client. This assume a significant baseline knowledge of how Kafka works. Note from the presentation are below along with the video embedded (start watching at 01:51:09). You can find the slides here (download for animations!).
The presentation was broken up into three parts:
At the last Kafka meetup at LinkedIn in Mountain View, I presented some work we’ve done at SignalFx to get significant performance gains by writing our own consumer/client. This assume a significant baseline knowledge of how Kafka works. Note from the presentation are below along with the video embedded (start watching at 01:51:09). You can find the slides here (download for animations!).
The presentation was broken up into three parts:
- Why we wrote a consumer
- How modern hardware works
- Three optimizations on the consumer
Container Tidbits: When Should I Break My Application into Multiple Containers? – Red Hat Enterprise Linux Blog
Container Tidbits: When Should I Break My Application into Multiple Containers? – Red Hat Enterprise Linux Blog:
There is a lot of confusion around which pieces of your application you should break into multiple containers and why. I recently responded to this thread on the Docker user mailing list which led me to writing today’s post. In this post I plan to examine an imaginary Java application that historically ran on a single Tomcat server and to explain why I would break it apart into separate containers. In an attempt to make things interesting – I will also aim to justify this action (i.e. breaking the application into separate containers) with data and (engineering) logic… as opposed to simply stating that “there is a principle” and that one must adhere to it all of the time.
Let’s take an example Java application made up of the following two components:
As mentioned, this application historically ran in a single Tomcat server and the two components were communicating over a REST-based API… so the question becomes:
Should I break this application into multiple containers?
Yes. I believe this application should be decomposed into two different Docker containers… but only after careful consideration.
There is a lot of confusion around which pieces of your application you should break into multiple containers and why. I recently responded to this thread on the Docker user mailing list which led me to writing today’s post. In this post I plan to examine an imaginary Java application that historically ran on a single Tomcat server and to explain why I would break it apart into separate containers. In an attempt to make things interesting – I will also aim to justify this action (i.e. breaking the application into separate containers) with data and (engineering) logic… as opposed to simply stating that “there is a principle” and that one must adhere to it all of the time.
Let’s take an example Java application made up of the following two components:
- A front-end application built on the Struts Web Framework
- A back-end REST API server built on Java EE
As mentioned, this application historically ran in a single Tomcat server and the two components were communicating over a REST-based API… so the question becomes:
Should I break this application into multiple containers?
Yes. I believe this application should be decomposed into two different Docker containers… but only after careful consideration.
Git & Scrum: Workflows that work - O'Reilly Media
Workflows that work - O'Reilly Media:
I love working with teams of people to hash out a plan of action—the more sticky notes and whiteboards the better. Throughout the process, there may be a bit of arguing, and some compromises made, but eventually you get to a point where people can agree on a basic process. Everyone gets back to their desks, clear about the direction they need to go in and suddenly, one by one, people start asking, "But how do I start?" The more cues you can give your team to get working, the more they can focus on the hard bits. Version control should never be the hard part.
By the end of this chapter, you will be able to create step-by-step documentation covering:
This chapter is essentially a set of abstracted case studies on how I have effectively used Git while working in teams. You will notice my strong preference for Agile methodologies, in particular Scrum, in this chapter.
I love working with teams of people to hash out a plan of action—the more sticky notes and whiteboards the better. Throughout the process, there may be a bit of arguing, and some compromises made, but eventually you get to a point where people can agree on a basic process. Everyone gets back to their desks, clear about the direction they need to go in and suddenly, one by one, people start asking, "But how do I start?" The more cues you can give your team to get working, the more they can focus on the hard bits. Version control should never be the hard part.
By the end of this chapter, you will be able to create step-by-step documentation covering:
- Basic workflow
- Integration branches
- Release schedules
- Post-launch hotfixes
This chapter is essentially a set of abstracted case studies on how I have effectively used Git while working in teams. You will notice my strong preference for Agile methodologies, in particular Scrum, in this chapter.
Friday, 18 March 2016
SDN OpenDaylight Project
OpenDaylight Project - Wikipedia, the free encyclopedia:
The OpenDaylight Project is a collaborative open source project hosted by The Linux Foundation. The goal of the project is to accelerate the adoption of software-defined networking (SDN) and create a solid foundation for Network Functions Virtualization (NFV). The software is written in Java.
The OpenDaylight Project is a collaborative open source project hosted by The Linux Foundation. The goal of the project is to accelerate the adoption of software-defined networking (SDN) and create a solid foundation for Network Functions Virtualization (NFV). The software is written in Java.
The Path to SDN
http://go.bigswitch.com/rs/974-WXR-561/images/The%20Path%20To%20SDN%20Final.pdf
Networking has seen more innovation in the past two years than in the past 20 years. This innovation is coming from the perfect storm of:
• ‘Software-Defined Networking,’ a new architecture in networking
• ‘White box’ and ‘brite box’ switching
• The popularization of advanced datacenter designs pioneered by Google, Facebook, Amazon, and other hyperscale operators
A Look Back at How It All Started
Bruce Davie,: Is SDN Necessary?
Is SDN Necessary?:
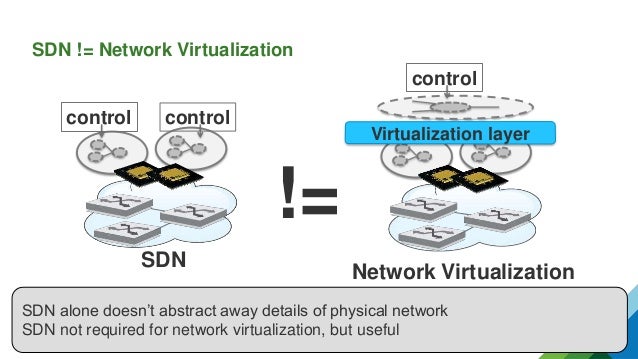
SDN != Network Virtualization SDN control control Network Virtualization != Virtualization layer control SDN alone doesn’t abstract away details of physical network SDN not required for network virtualization, but useful
'via Blog this'
SDN != Network Virtualization SDN control control Network Virtualization != Virtualization layer control SDN alone doesn’t abstract away details of physical network SDN not required for network virtualization, but useful
{kind=link}
'via Blog this'
Command Query Responsibility Segregation and Event Sourcing
CQRS: "Command Query Responsibility Segregation"
The change that CQRS introduces is to split that conceptual model into separate models for update and display, which it refers to as Command and Query respectively following the vocabulary ofCommandQuerySeparation. The rationale is that for many problems, particularly in more complicated domains, having the same conceptual model for commands and queries leads to a more complex model that does neither well.
By separate models we most commonly mean different object models, probably running in different logical processes, perhaps on separate hardware. A web example would see a user looking at a web page that's rendered using the query model. If they initiate a change that change is routed to the separate command model for processing, the resulting change is communicated to the query model to render the updated state.
There's room for considerable variation here. The in-memory models may share the same database, in which case the database acts as the communication between the two models. However they may also use separate databases, effectively making the query-side's database into a real-time ReportingDatabase. In this case there needs to be some communication mechanism between the two models or their databases.
The two models might not be separate object models, it could be that the same objects have different interfaces for their command side and their query side, rather like views in relational databases. But usually when I hear of CQRS, they are clearly separate models.

The change that CQRS introduces is to split that conceptual model into separate models for update and display, which it refers to as Command and Query respectively following the vocabulary ofCommandQuerySeparation. The rationale is that for many problems, particularly in more complicated domains, having the same conceptual model for commands and queries leads to a more complex model that does neither well.
By separate models we most commonly mean different object models, probably running in different logical processes, perhaps on separate hardware. A web example would see a user looking at a web page that's rendered using the query model. If they initiate a change that change is routed to the separate command model for processing, the resulting change is communicated to the query model to render the updated state.
There's room for considerable variation here. The in-memory models may share the same database, in which case the database acts as the communication between the two models. However they may also use separate databases, effectively making the query-side's database into a real-time ReportingDatabase. In this case there needs to be some communication mechanism between the two models or their databases.
The two models might not be separate object models, it could be that the same objects have different interfaces for their command side and their query side, rather like views in relational databases. But usually when I hear of CQRS, they are clearly separate models.
SSD reliability in the real world: Google's experience | ZDNet
SSD reliability in the real world: Google's experience | ZDNet:
- Ignore Uncorrectable Bit Error Rate (UBER) specs. A meaningless number.
- Good news: Raw Bit Error Rate (RBER) increases slower than expected from wearout and is not correlated with UBER or other failures.
- High-end SLC drives are no more reliable that MLC drives.
- Bad news: SSDs fail at a lower rate than disks, but UBER rate is higher (see below for what this means).
- SSD age, not usage, affects reliability.
- Bad blocks in new SSDs are common, and drives with a large number of bad blocks are much more likely to lose hundreds of other blocks, most likely due to die or chip failure.
- 30-80 percent of SSDs develop at least one bad block and 2-7 percent develop at least one bad chip in the first four years of deployment.
Git/GitHub: Kindly Closing Pull Requests
Kindly Closing Pull Requests:
Getting your first pull request from an outside contributor on GitHub is an exciting experience. Someone cared enough about the problem you were solving to check it out themselves, change something, and contribute that change back to your project. When your project has a relatively small number of high-quality, desirable incoming pull requests it is easy to happily merge them.
Where things can become more difficult is when your project becomes more notable and the quality, desirability, or number of pull requests you receive causes difficulties. Now the positive feeling you had about the time people spent can be reversed; you don't want to reject someone's work when they have already spent the time to get it included.
Let's discuss some common types of pull requests that can be closed and how to do so in a way that encourages positive behavior in your community (rather than discouraging participation).
Getting your first pull request from an outside contributor on GitHub is an exciting experience. Someone cared enough about the problem you were solving to check it out themselves, change something, and contribute that change back to your project. When your project has a relatively small number of high-quality, desirable incoming pull requests it is easy to happily merge them.
Where things can become more difficult is when your project becomes more notable and the quality, desirability, or number of pull requests you receive causes difficulties. Now the positive feeling you had about the time people spent can be reversed; you don't want to reject someone's work when they have already spent the time to get it included.
Let's discuss some common types of pull requests that can be closed and how to do so in a way that encourages positive behavior in your community (rather than discouraging participation).
tcpdump is amazing - Julia Evans
tcpdump is amazing - Julia Evans:
Let's suppose you have some slow HTTP requests happening on your machine, and you want to get a distribution of how slow they are. You could add some monitoring somewhere inside your program. Or! You could use tcpdump. Here's how that works!
The secret here is that we can use tcpdump to record network traffic, and then use a tool that we're less scared of (Wireshark) to analyze it on our laptop after.
Let's suppose you have some slow HTTP requests happening on your machine, and you want to get a distribution of how slow they are. You could add some monitoring somewhere inside your program. Or! You could use tcpdump. Here's how that works!
- Use tcpdump to record network traffic on the machine for 10 minutes
- analyze the recording with Wireshark
- be a wizard
The secret here is that we can use tcpdump to record network traffic, and then use a tool that we're less scared of (Wireshark) to analyze it on our laptop after.
Thursday, 10 March 2016
Monday, 7 March 2016
Friday, 4 March 2016
fabric8io/kansible: Kansible lets you orchestrate operating system processes on Windows or any Unix in the same way as you orchestrate your Docker containers with Kubernetes by using Ansible to provision the software onto hosts and Kubernetes to orchestate the processes
Thursday, 3 March 2016
Subscribe to:
Comments (Atom)